Hay un punto en la vida de todo MSP donde el crecimiento empieza a doler.
Entran más clientes, entran más equipos, y de repente el equipo técnico está al tope. El primer instinto es contratar. Y a veces tiene sentido.
Pero muchas veces el problema no es que falten técnicos. Es que el tiempo de los que ya tienes está mal distribuido: demasiado en tareas repetitivas, demasiado reaccionando a lo mismo de siempre, demasiado poco en lo que realmente mueve el negocio.
Antes de contratar, vale la pena preguntarse: ¿ya estamos aprovechando bien el equipo que tenemos?
1) El problema no es la carga — es cómo está distribuida
Un MSP típico tiene dos tipos de trabajo.
El trabajo que tiene que hacer un técnico —diagnóstico complejo, decisiones que requieren criterio, interacción con el cliente— y el trabajo que en teoría podría hacerse solo, pero que nadie automatizó todavía.
El segundo tipo se acumula. Reiniciar servicios, limpiar temporales, revisar el estado de los equipos uno por uno, aplicar configuraciones básicas, responder siempre el mismo tipo de ticket.
Ese trabajo no desaparece cuando contratas a alguien nuevo. Solo se redistribuye… hasta que el nuevo también llega al tope.
La palanca real no es más personas. Es reducir el tiempo que cada persona pasa en trabajo que podría hacerse de otra forma.
2) Automatiza primero lo que más se repite
No hace falta automatizar todo de golpe. Basta con empezar por lo que más se repite.
¿Qué tipo de ticket llega todos los días? ¿Qué pasos sigues siempre para resolverlo? ¿Qué parte de ese proceso podría ejecutarse con un script?
El impacto de la automatización no se mide en lo espectacular de la tarea —se mide en la frecuencia. Algo que te quita 10 minutos pero pasa 30 veces al mes son 5 horas devueltas al equipo cada mes. Sin contratar a nadie.
Y cuando eso se convierte en estándar, el técnico deja de ser el que ejecuta tareas rutinarias y empieza a ser el que supervisa que se ejecuten bien.
3) Las alertas proactivas reducen tickets antes de que lleguen
Cada ticket que no entra es tiempo que no se gasta.
La lógica es simple: si detectas que el disco de un equipo está al 88% y actúas antes de que llegue al 100%, ese usuario nunca abre un ticket. El técnico nunca atiende esa interrupción. El problema se resuelve antes de que exista.
Multiplicado por toda la flota, ese modelo cambia radicalmente cuántos tickets entran por semana.
Los MSPs que operan de forma proactiva no tienen menos trabajo —tienen un trabajo diferente: planificado, controlado, sin las urgencias de última hora que queman al equipo.
4) Acciones en lote: resuelves 20 equipos en el tiempo de uno
Hay una diferencia enorme entre atender un problema en un equipo y atender el mismo problema en 20 equipos.
Sin las herramientas adecuadas, son 20 sesiones remotas, 20 veces los mismos pasos, 20 veces la misma espera. Eso escala fatal.
Con acciones en lote, seleccionas los equipos afectados, ejecutas la acción una vez y recibes el resultado de todos. El tiempo por equipo cae drásticamente y el técnico puede atender volúmenes que antes requerían el doble de personas.
Esto aplica a actualizaciones, scripts de mantenimiento, configuraciones, remediaciones de seguridad. Cualquier cosa que hoy haces de forma individual y repetida es candidata a hacerse en lote.
5) Estandariza para que no todo dependa del técnico que "se la sabe"
En muchos MSPs, hay un técnico —a veces dos— que sabe exactamente qué hacer en cada situación. Esa persona es valiosa y también es un riesgo.
Cuando el conocimiento vive en la cabeza de alguien y no en procesos, procedimientos o automatizaciones, el equipo tiene un cuello de botella que no desaparece contratando más gente. Solo se mueve.
La estandarización no es burocracia. Es lo que permite que un técnico nuevo sea productivo en días, que el equipo opere de forma consistente con cada cliente, y que escalar no signifique que todo dependa de que "el que sabe" esté disponible.
Cierre
Contratar es a veces la respuesta correcta. Pero antes de llegar ahí, vale la pena exprimir bien lo que ya tienes.
Automatización, proactividad, acciones en lote y estandarización no son lujos de un MSP grande. Son las palancas que permiten que un MSP mediano opere como uno grande sin duplicar su nómina.
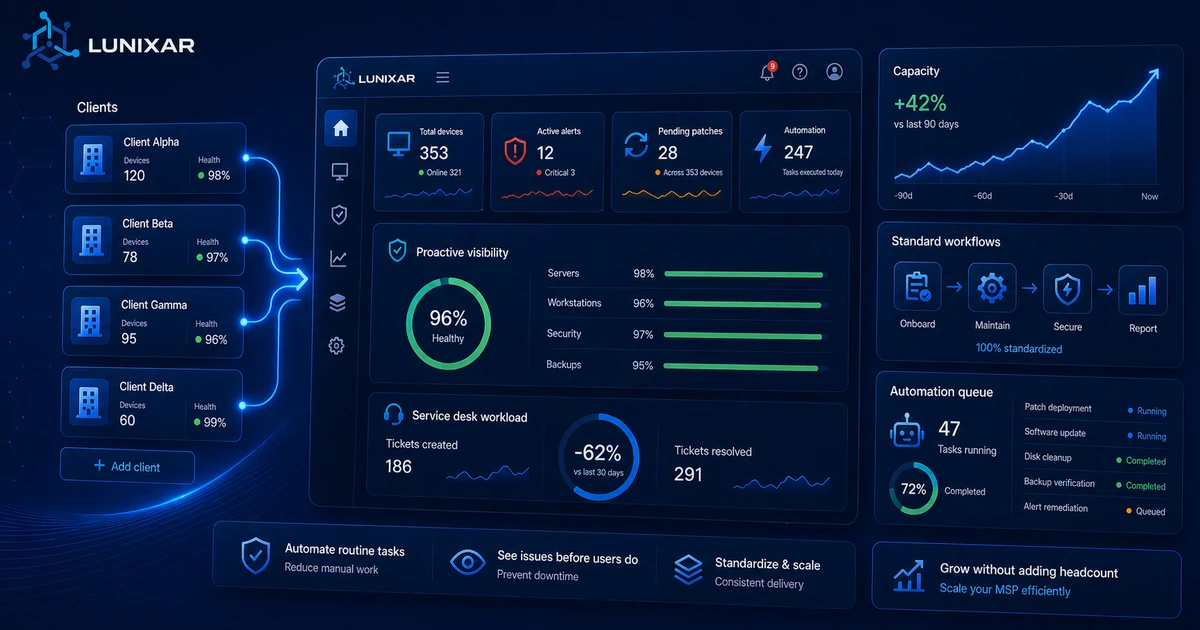
Lunixar RMM está diseñado para que tu equipo atienda más dispositivos con menos fricción: alertas proactivas que reducen tickets, visibilidad de flota en tiempo real y acciones ejecutables directamente desde la consola.
Si quieres ver cómo se ve eso en la práctica, tienes 2 semanas de prueba gratuita para comprobarlo.


