There's a point in every MSP's growth where things start to hurt.
More clients come in, more devices get added, and suddenly the technical team is maxed out. The first instinct is to hire. And sometimes that's the right call.
But a lot of the time, the problem isn't a shortage of technicians — it's that the ones you already have are spending time in the wrong places. Too much on repetitive tasks, too much reacting to the same issues over and over, too little on what actually moves the business forward.
Before you post that job listing, it's worth asking: are we getting the most out of the team we already have?
1) The problem isn't the workload — it's how it's distributed
Every MSP has two kinds of work.
Work that actually requires a technician — complex diagnosis, judgment calls, client conversations — and work that could theoretically run itself, but nobody's automated it yet.
The second kind piles up. Restarting services, clearing temp files, checking device status one by one, applying basic configs, handling the same ticket type for the tenth time this month.
That work doesn't go away when you hire someone new. It just redistributes… until the new person hits their ceiling too.
The real lever isn't more people. It's reducing the time each person spends on work that could be handled differently.
2) Automate what repeats most — start there
You don't have to automate everything at once. You just need to start with what happens most.
What type of ticket comes in every day? What steps does your team always follow to close it? What part of that process could run as a script?
Automation's impact isn't measured by how impressive the task is — it's measured by frequency. Something that takes 10 minutes but happens 30 times a month is 5 hours back for the team every month. Without hiring anyone.
And once that becomes standard, the technician stops being the person who runs routine tasks and becomes the person who makes sure they're running well.
3) Proactive alerts cut tickets before they arrive
Every ticket that doesn't come in is time that doesn't get spent.
The logic is simple: if you catch a device's disk at 88% and act before it hits 100%, that user never opens a ticket. The technician never handles that interruption. The problem gets resolved before it exists.
Multiply that across an entire fleet, and that model radically changes how many tickets come in per week.
MSPs that operate proactively don't have less work — they have different work: planned, controlled, without the last-minute fires that burn teams out.
4) Bulk actions: handle 20 devices in the time it takes to handle one
There's a huge difference between fixing a problem on one device and fixing the same problem on 20.
Without the right tools, that's 20 remote sessions, the same steps 20 times, the same waiting 20 times. That doesn't scale.
With bulk actions, you select the affected devices, run the action once, and get results for all of them. Time per device drops dramatically, and a single technician can handle volumes that used to require twice the headcount.
This applies to updates, maintenance scripts, configurations, security remediations — anything you currently do one device at a time is a candidate for doing in bulk.
5) Standardize so not everything depends on the one tech who "knows how"
In a lot of MSPs, there's one person — sometimes two — who knows exactly what to do in every situation. That person is valuable. They're also a risk.
When knowledge lives in someone's head instead of in processes, runbooks, or automations, the team has a bottleneck that doesn't go away when you hire more people. It just shifts.
Standardization isn't bureaucracy. It's what lets a new tech become productive in days, lets the team handle every client consistently, and means scaling doesn't depend on "the person who knows" being available.
Closing
Hiring is sometimes the right answer. But before you get there, it's worth squeezing more out of what you already have.
Automation, proactivity, bulk actions, and standardization aren't luxuries for a large MSP. They're the levers that let a mid-sized MSP operate like a large one without doubling the payroll.
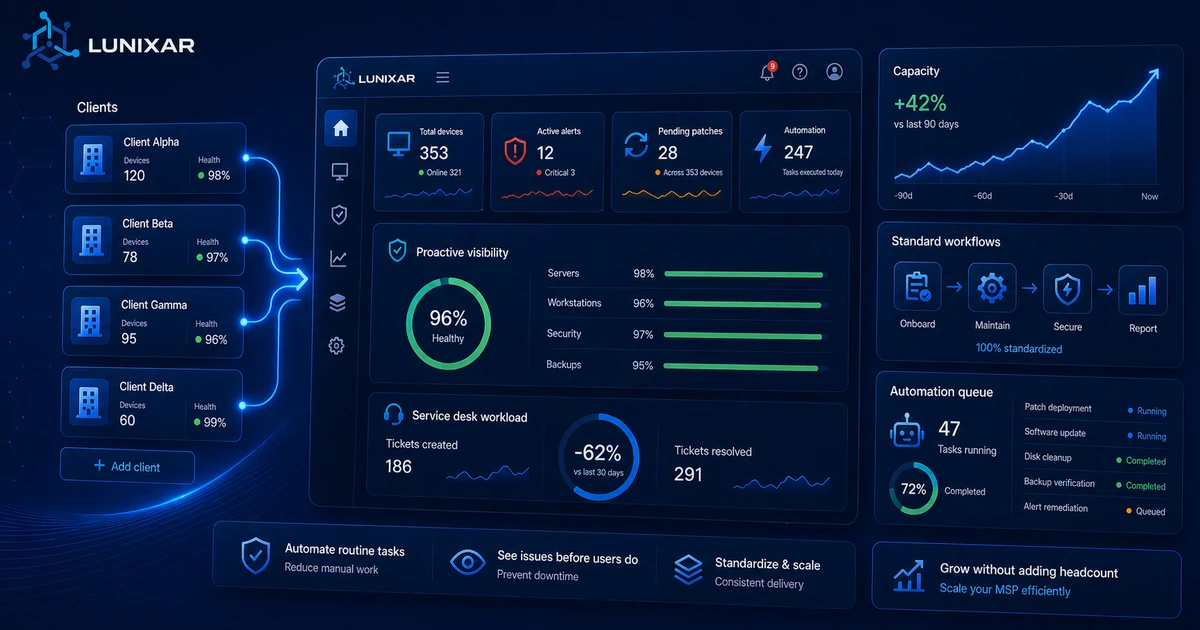
Lunixar RMM is built for exactly that: proactive alerts that reduce tickets, real-time fleet visibility, and actions you can run directly from the console — so your team handles more with less friction.
You have 2 weeks to try it free. No credit card required.


