Hay lunes que arrancan solos.
Tres mensajes antes del café.
Un cliente diciendo "está lento".
Y una consola llena de alertas que nadie revisó el viernes.
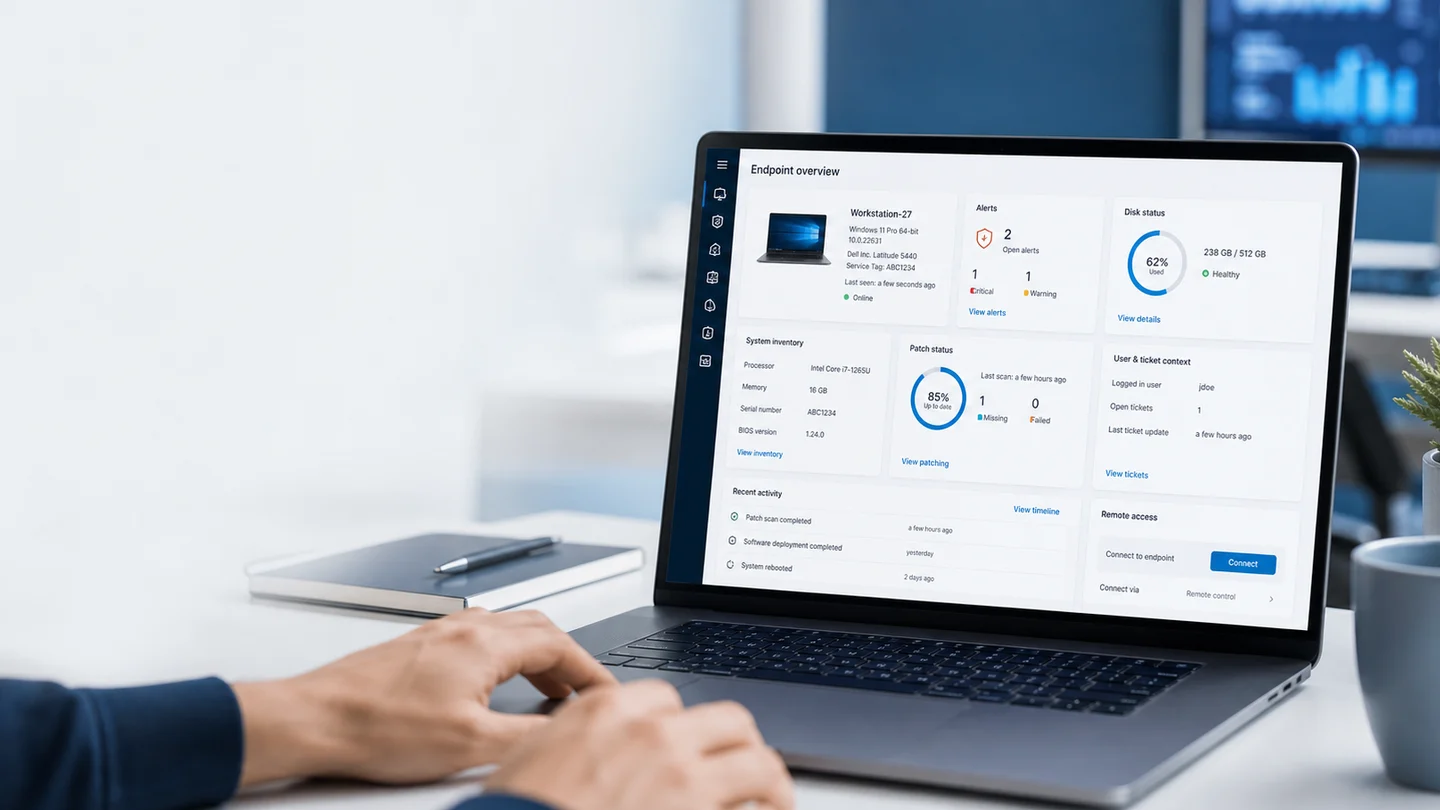
La diferencia entre empezar la semana con control o con caos no es magia. Es una rutina corta. Una revisión semanal que te diga qué está sano, qué está raro y qué necesita acción antes de que se convierta en ticket.
Esta guía está pensada para MSPs pequeños y departamentos internos de TI. No es un ritual burocrático. Es una forma práctica de usar tu RMM como tablero de mando los lunes.
Como base externa, vale la pena mirar tres referencias: la guía de NIST sobre planeación de gestión de parches empresarial, los Cybersecurity Performance Goals de CISA y el catálogo Known Exploited Vulnerabilities de CISA. Traducido a operación diaria: inventario claro, parches priorizados, evidencia de explotación y seguimiento constante.
1) Dispositivos offline: quién desapareció del mapa
Empieza por lo simple: qué dispositivos no han reportado.
Un equipo offline puede ser normal. Una laptop apagada, una PC fuera de horario, un equipo que el usuario dejó en casa.
Pero también puede ser:
- un agente roto,
- una máquina sin red,
- un endpoint retirado sin aviso,
- un servidor que dejó de responder,
- o un cliente completo con problema de conectividad.
La clave no es entrar en pánico. La clave es separar lo esperado de lo raro.
Para un MSP, esto también sirve para detectar clientes con baja disciplina operativa: equipos que aparecen y desaparecen, agentes que no vuelven, máquinas que nadie sabe quién usa.
2) Alertas abiertas: lo viejo te cobra factura
Las alertas del lunes no son todas iguales.
Hay alertas nuevas, alertas repetidas y alertas viejas que alguien dejó "para luego".
Ordénalas así:
- nuevas desde el viernes: pueden indicar algo que pasó fuera de horario;
- repetidas en el mismo equipo: suelen apuntar a causa raíz no resuelta;
- abiertas por más de una semana: ya son deuda operativa;
- seguridad o autenticación: no se mezclan con ruido normal.
En Lunixar RMM, alertas como LowDiskSpace, DiskSmartPredictedFailure, AntivirusDisabled, MalwareDetected, FailedLoginBurst, AccountLockoutBurst, SecurityLogCleared o PrivilegedGroupMembershipChange no deberían vivir en el mismo cajón. Algunas son mantenimiento. Otras son investigación.
3) Disco y salud del hardware: antes de que el usuario pierda trabajo
Un disco bajo no parece urgente.
Hasta que ya no hay espacio para actualizaciones, logs, temporales o archivos de trabajo.
Un SMART con riesgo no parece urgente.
Hasta que el disco falla y ahora el problema es restauración, no prevención.
El lunes revisa:
- equipos con poco espacio libre;
- dispositivos con crecimiento rápido de uso de disco;
- alertas de salud de disco;
- servidores o PCs de usuarios clave con almacenamiento al límite;
- patrones repetidos por cliente o departamento.
Aquí el inventario ayuda mucho. Si ves que un equipo cambió de software, empezó a generar logs o tiene nuevos archivos pesados, ya tienes contexto antes de conectarte.
4) Parches: qué falta, qué duele y qué se debe priorizar
NIST trata la gestión de parches como mantenimiento preventivo, no como reacción de último minuto. Esa idea es importante: los parches no son una tarea aislada, son parte de mantener la operación sana.
El lunes revisa:
- dispositivos con parches pendientes;
- endpoints que fallaron al actualizar;
- sistemas que llevan más tiempo sin mantenimiento;
- clientes o áreas con mayor exposición;
- vulnerabilidades con evidencia de explotación pública.
Aquí entra CISA KEV: si una vulnerabilidad está en el catálogo de Known Exploited Vulnerabilities, no es solo "alta severidad". Ya hay evidencia de explotación en el mundo real. Esa lista te ayuda a decidir qué va primero cuando todo parece urgente.
5) Seguridad: señales que no deben mezclarse con mantenimiento
El lunes también es buen momento para revisar cambios de seguridad que pasaron mientras nadie estaba mirando de cerca.
Pon atención a:
- antivirus desactivado;
- malware detectado;
- exclusiones nuevas en Defender;
- múltiples inicios de sesión fallidos;
- bloqueos de cuenta en volumen;
- grupos privilegiados modificados;
- logs de seguridad borrados;
- política de auditoría cambiada.
No todas estas señales significan incidente. Pero todas merecen contexto.
Si ves AntivirusDisabled, revisa si hubo instalación nueva. Si ves FailedLoginBurst, revisa origen y cuenta. Si ves SecurityLogCleared, no lo cierres como mantenimiento sin investigar.
6) Inventario: qué cambió sin que te avisaran
El inventario no es solo una lista bonita.
Es la memoria operativa de tu flota.
El lunes revisa:
- software nuevo instalado;
- software removido;
- cambios de hardware;
- equipos nuevos;
- equipos que ya no deberían estar activos;
- diferencias raras entre snapshots.
Esto ayuda mucho en MSPs porque los clientes cambian cosas sin avisar. También ayuda en TI interno porque muchas veces el usuario instala algo, conecta hardware o mueve una máquina sin abrir ticket.
7) Acciones de seguimiento: qué se hace hoy, qué se agenda y qué se cierra
Una revisión semanal no sirve si termina en "hay que verlo".
Termina con tres listas:
- acción hoy: seguridad, disco crítico, servidores, parches de alto riesgo;
- acción programada: mantenimiento, actualizaciones, limpieza, seguimiento con usuario;
- cerrar o documentar: alertas ya resueltas, equipos retirados, falsos positivos confirmados.
Para un MSP, esta lista también es buen material para demostrar valor al cliente: "detectamos esto, resolvimos esto, queda esto pendiente". Para TI interno, ayuda a justificar trabajo preventivo que normalmente nadie ve.
Cierre
Un buen lunes en TI no significa cero problemas.
Significa saber cuáles importan primero.
Una rutina semanal de RMM te ayuda a pasar de reaccionar a priorizar: dispositivos offline, alertas, disco, parches, seguridad, inventario y seguimiento. No necesitas revisar todo con la misma profundidad. Necesitas un orden.
Lunixar RMM encaja en ese flujo porque conecta monitoreo, inventario, alertas, seguridad y acciones operativas en una sola consola. Si hoy tu lunes depende de chats, hojas de cálculo y memoria, una prueba de 2 semanas puede ayudarte a convertirlo en proceso.
Lecturas relacionadas para seguir
Si quieres llevar esta rutina a una operación más completa, sigue con estas guías: