Hay dos tipos de equipos de TI.
Los que se enteran de que algo falló cuando el usuario ya lleva rato sufriendo.
Y los que se enteran antes.
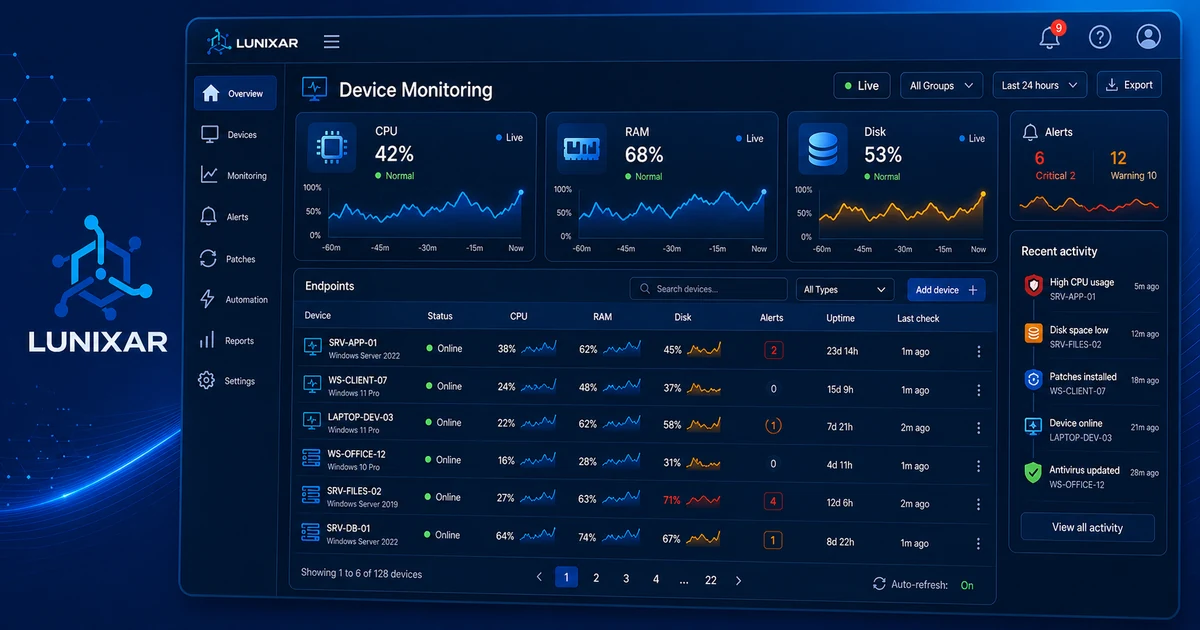
La diferencia entre los dos casi siempre empieza en el mismo lugar: saber qué tienes.
Y no me refiero a tener una lista de Excel con los equipos. Me refiero a saber de verdad: qué disco tiene la compu que "siempre va lento", cuánta RAM libre tiene en este momento, qué software se instaló la semana pasada sin que nadie avisara.
Sin eso, operas adivinando. Y adivinar en TI es caro.
1) No puedes proteger lo que no conoces
Esta es la regla más básica de la gestión de TI. Y también la que más se ignora.
Pregunta directa: ¿cuántos equipos tienes bajo administración ahora mismo? ¿Cuál es la versión exacta de Windows en cada uno? ¿Qué software tienen instalado? ¿Cuánta RAM le queda libre a la compu que "siempre va lento"? ¿Cuándo fue la última vez que alguien revisó el estado de los discos?
Sin inventario activo, esas preguntas se responden de cuatro formas: con suerte, con tiempo perdido, yendo presencial, o sencillamente no se responden.
Con inventario en tiempo real, la respuesta está ahí antes de que termines de formular la pregunta.
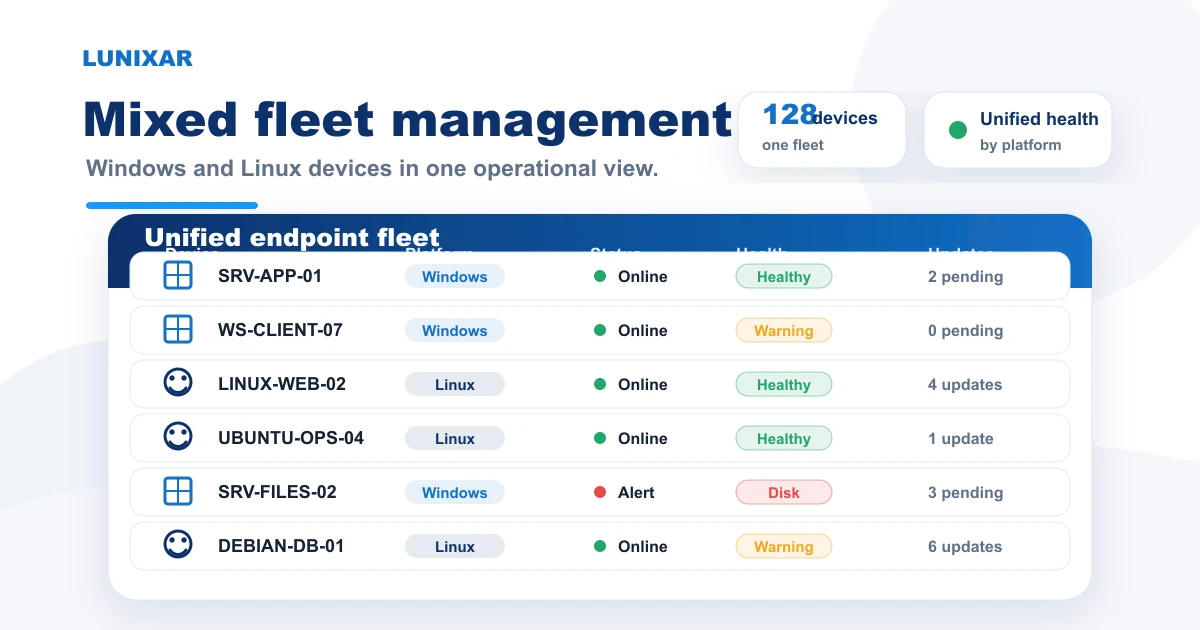
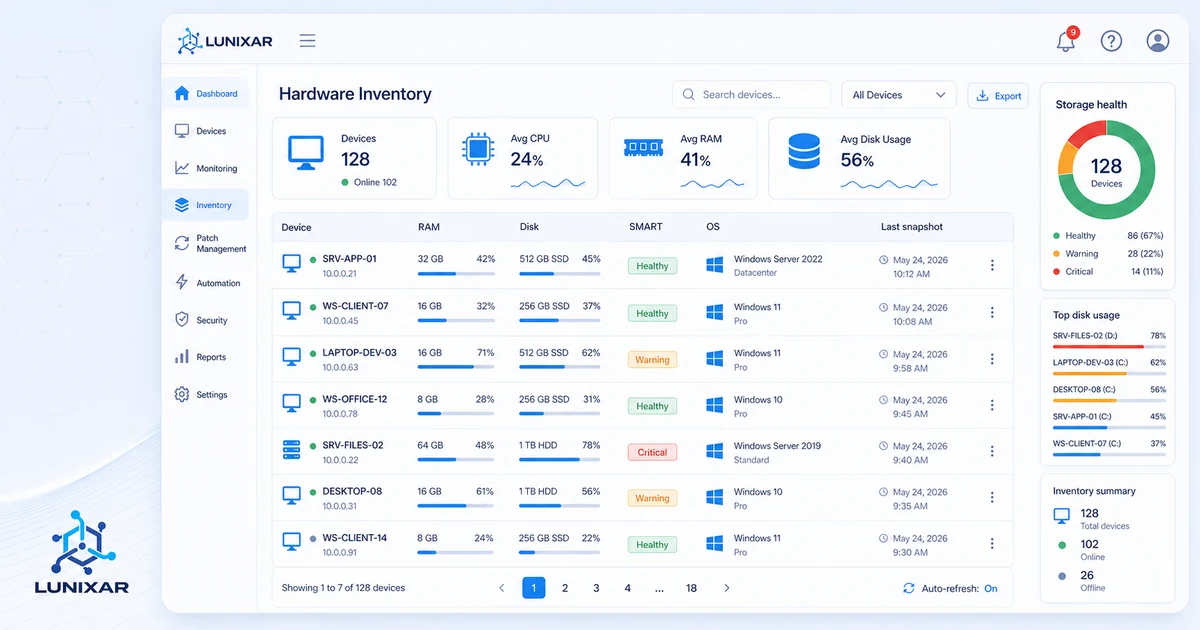
2) Hardware, software y snapshots: tres capas que trabajan juntas
Un inventario útil no se queda en "qué hardware tiene el equipo". Necesita al menos tres capas.
Hardware: procesador, RAM, almacenamiento, pantallas, periféricos. Lo que físicamente existe en el dispositivo y su estado actual.
Software: qué apps están instaladas, en qué versión, y cuáles definitivamente no deberían estar. Esta capa es crítica para seguridad, licencias y soporte.
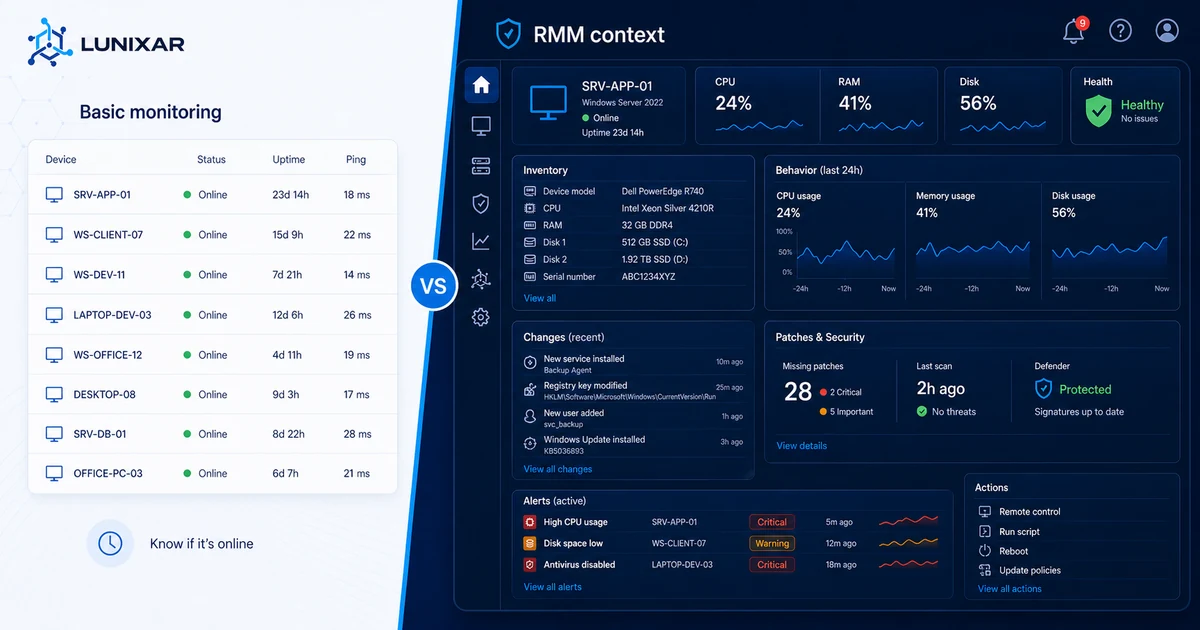
Snapshots: el historial. No solo "qué tiene hoy", sino "qué tenía la semana pasada, qué cambió, y cuándo". Cuando algo falla, el snapshot te dice exactamente qué era diferente antes.
Y los snapshots son especialmente de oro cuando el equipo "de repente dejó de funcionar bien". Sin historial, el técnico llega a investigar desde cero. Con snapshots, compara el estado actual con el anterior y encuentra la diferencia en segundos.
3) SMART: el disco te avisa antes de fallar, si lo escuchas
Los discos no fallan de golpe. Fallan con señales… que casi nadie está leyendo.
SMART (Self-Monitoring, Analysis and Reporting Technology) viene integrado en la mayoría de los discos modernos. Mide atributos internos: sectores reasignados, errores de lectura, temperatura, tiempo de arranque. Métricas que te dicen si el disco está sano o si ya está empezando a morirse.
El problema es que esas señales son invisibles si nadie las está leyendo.
Un agente que analiza atributos SMART puede avisarte cuando un disco muestra indicios de fallo inminente, antes de que ocurra la pérdida de datos. Eso te da una ventana para actuar: respaldo, reemplazo planificado, migración de datos, aviso al usuario. Todo con tiempo.
Sin esa visibilidad, el flujo típico es: el disco falla → el usuario pierde trabajo → tú corres a ver si se puede recuperar algo.
Con visibilidad SMART: el disco empieza a degradarse → te llega una alerta → actúas antes del desastre.
4) El inventario como primer paso en cualquier ticket
Cuando llega un ticket, lo primero que necesitas no es abrir una sesión remota. Es contexto.
- ¿Qué sistema operativo tiene y en qué versión exacta?
- ¿Cuánta memoria libre hay en este momento?
- ¿Hay actualizaciones pendientes?
- ¿Se instaló algo nuevo esta semana?
- ¿Cuándo fue la última vez que estuvo online?
Con inventario activo, todo eso ya tiene respuesta antes de conectarte. Reduces el tiempo de diagnóstico, eliminas el "mándame una captura" de ida y vuelta, y llegas con hipótesis en lugar de llegar a improvisar.
La diferencia entre el técnico que "investiga" y el que "verifica" está, casi siempre, en la calidad de su inventario.
5) Inventario + alertas: la combinación que cambia la operación
El inventario solo te dice el estado. Las alertas te avisan cuando ese estado cambia de forma crítica.
Cuando los dos trabajan juntos, la operación deja de ser reactiva:
- Poco espacio en disco → el inventario muestra el nivel, la alerta avisa cuando cruza el umbral
- Software inesperado instalado → el snapshot captura el cambio, la comparación lo hace visible
- Disco degradándose → los atributos SMART muestran la tendencia, la alerta llega antes del fallo
Ese ciclo —inventario que informa, alerta que avisa, técnico que actúa— es lo que distingue a un equipo proactivo de uno que se entera cuando ya es tarde.
Y lo mejor: no necesitas más personas para llegar ahí. Solo mejor visibilidad.
Cierre
Si todavía te estás enterando del estado de tus equipos cuando el usuario te marca, el inventario es el primer problema a resolver.
No porque sea la solución a todo. Sino porque sin él, el resto —alertas, automatización, soporte remoto— trabaja a medias.
Lunixar RMM mantiene un inventario activo de hardware y software por dispositivo, con snapshots históricos y análisis SMART integrado en el agente. Todo desde la misma consola donde ya estás administrando el resto de tu flota.
Si quieres pasar de apagar fuegos a prevenirlos, el inventario es por donde se empieza.