Si usas Zabbix, PRTG, Nagios o algún sistema de monitoreo básico, sabes que funciona.
Te avisa cuando un servidor se cae. Te muestra si el disco está al tope. Te da una gráfica de uso de CPU a lo largo del tiempo.
Y por un tiempo, eso alcanza.
Pero hay un momento —y la mayoría de los MSPs y equipos de TI lo conocen— en que la alerta llega, ves que "algo falló", y sigues sin saber qué hacer, en qué equipo exactamente, ni por qué pasó.
Ahí es donde el monitoreo básico se queda corto. Y ahí es donde un RMM empieza a ser relevante.
1) El monitoreo básico te dice que algo pasó. Un RMM te dice qué, por qué y en qué equipo.
El monitoreo básico es bueno haciendo una cosa: avisarte cuando algo cruza un umbral.
CPU al 95% → alerta. Disco al 90% → alerta. Host no responde → alerta.
Pero la alerta es solo el punto de partida. Lo que viene después —diagnosticar, entender el contexto, decidir qué hacer— queda fuera de la herramienta. Tienes que conectarte, buscar logs, revisar qué está corriendo, preguntar al usuario qué pasó.
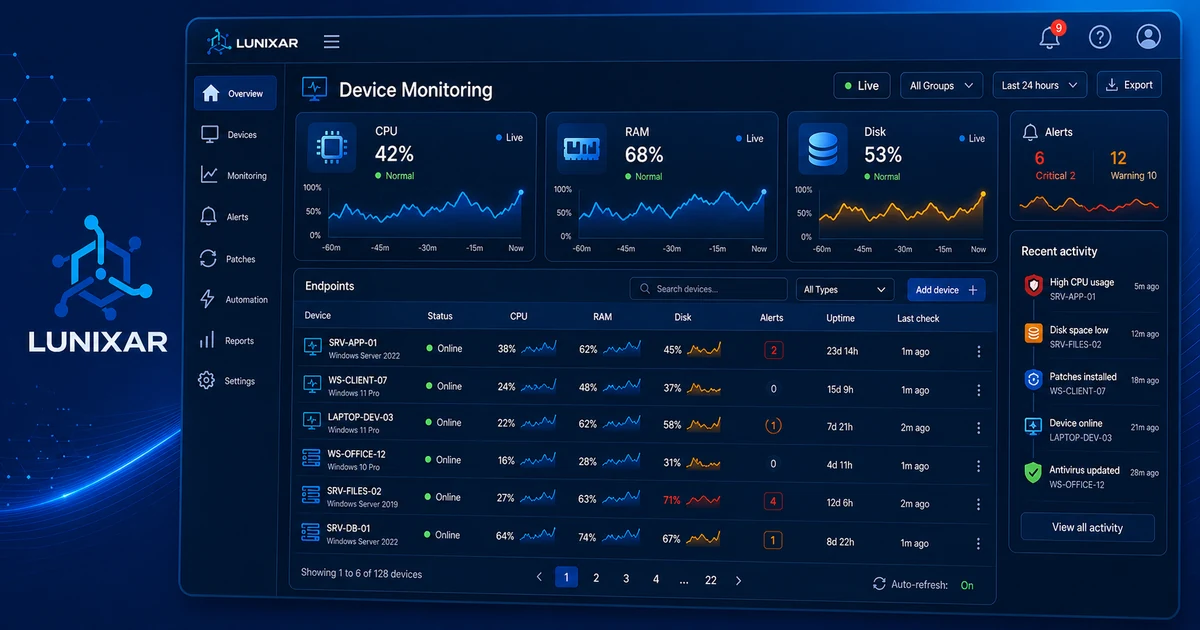
Con un RMM, ese contexto ya está ahí cuando llega la alerta: qué software tiene instalado el equipo, qué cambió en los últimos días, cuánta memoria libre había antes del pico, si hubo algún evento de sistema relacionado.
No es que el monitoreo básico esté mal. Es que llega hasta cierto punto y después te deja solo.
2) El monitoreo básico no sabe qué tiene instalado el equipo
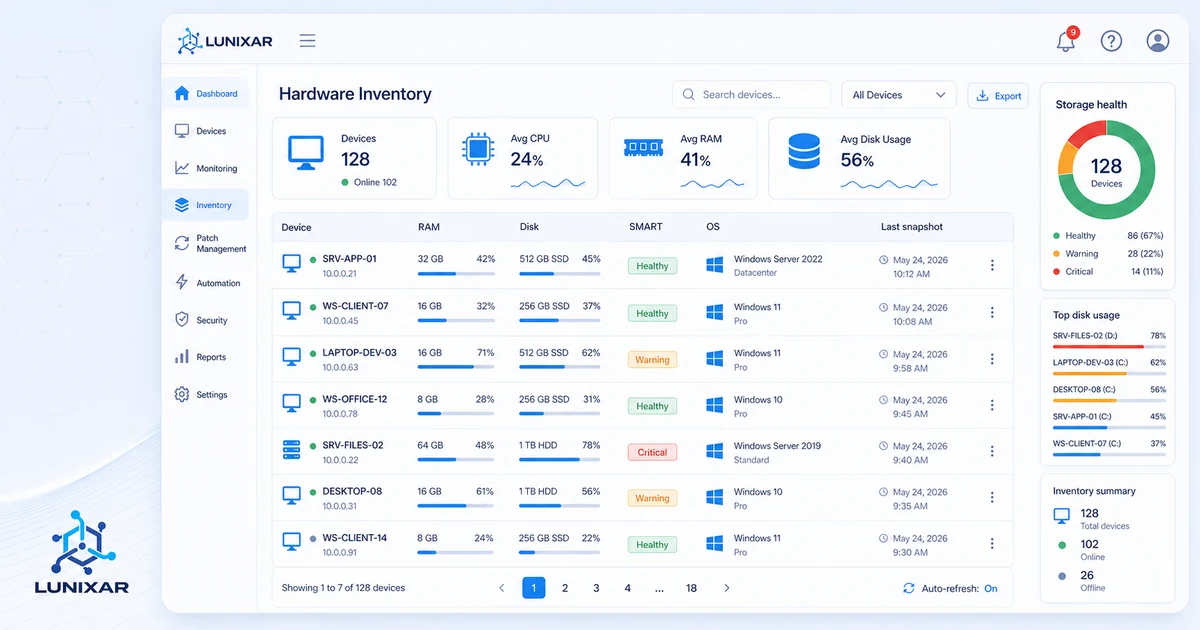
Una de las diferencias más concretas: el inventario.
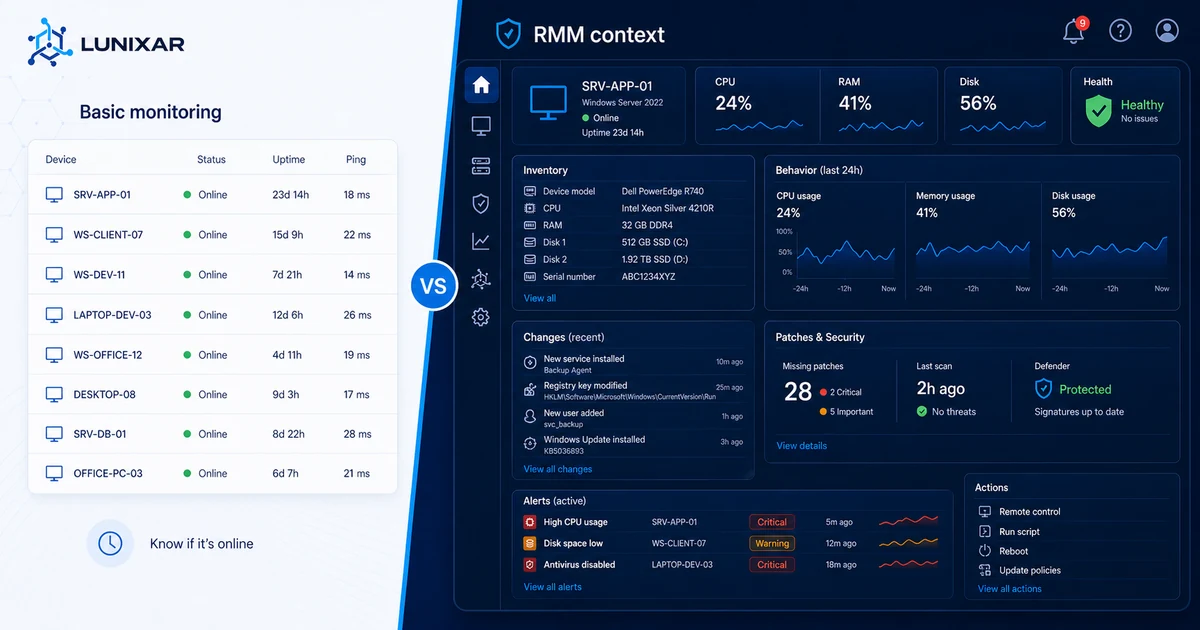
El monitoreo básico observa métricas. Un RMM conoce al equipo.
Conoce qué software tiene instalado, en qué versión, qué hardware lo compone, qué ha cambiado en los últimos días. Cuando llega una alerta de CPU alta, no tienes que conectarte a investigar qué proceso la está causando —ya tienes el contexto.
Y cuando un usuario reporta que "algo cambió" sin saber qué, el historial de snapshots te lo dice en segundos.
Ese nivel de conocimiento cambia completamente cómo trabajas: dejas de investigar desde cero en cada ticket y empiezas a verificar hipótesis que ya tienes antes de conectarte.
3) Del "está caído" al "ya lo arreglé"
El monitoreo básico te notifica. Un RMM te permite actuar.
Esa diferencia suena simple, pero cambia todo el flujo operativo.
Con monitoreo básico, el flujo es: alerta → abres otra herramienta → te conectas remotamente → investigas → actúas. Son varios pasos, varias herramientas, tiempo perdido entre cada uno.
Con un RMM, el flujo puede ser: alerta → ves el contexto → ejecutas la acción → listo. Todo desde la misma consola.
No porque el RMM haga magia, sino porque concentra visibilidad y capacidad de acción en un solo lugar. Eso reduce el tiempo entre "me enteré" y "lo resolví", que es exactamente lo que diferencia al soporte proactivo del reactivo.
4) La proactividad que el monitoreo básico no puede darte
El monitoreo básico es reactivo por diseño. Espera que algo cruce un umbral para avisarte.
Un RMM bien configurado va un paso antes: detecta tendencias, no solo umbrales puntuales. Un disco que lleva dos semanas creciendo de forma anormal no necesita llegar al 95% para que alguien lo note. El comportamiento ya es la señal.
Lo mismo con hardware: los atributos SMART de un disco te dicen si está empezando a degradarse mucho antes de que falle. Eso solo lo ves si tienes una herramienta que analiza ese tipo de datos por ti.
La diferencia entre monitoreo y gestión proactiva es la diferencia entre saber que el tanque está vacío y saber que llevas tres días sin echarle gasolina.
5) Cuándo el monitoreo básico ya no alcanza
El monitoreo básico alcanza bien cuando:
- Tienes pocos equipos y tiempo para investigar cada alerta manualmente
- El equipo que falla es fácil de identificar y acceder
- No necesitas trazabilidad ni historial de cambios
- El soporte es principalmente reactivo y está bien que lo sea
Empieza a quedarse corto cuando:
- La flota crece y no puedes investigar manualmente cada alerta
- Los tickets aumentan pero el tiempo no
- Quieres pasar de reactivo a proactivo sin duplicar el equipo
- Necesitas contexto antes de conectarte para no perder tiempo
No es que uno sea "mejor" que el otro en abstracto. Es que sirven para momentos distintos de la operación.
Cierre
El monitoreo básico es un buen punto de partida. El problema es quedarse ahí más tiempo del necesario.
Un RMM no reemplaza el monitoreo — lo extiende con contexto, historial e inventario, y le añade la capacidad de actuar sin saltar entre herramientas.
Lunixar RMM está diseñado para que esa transición se sienta natural: alertas que vienen con contexto, inventario activo por dispositivo y acciones ejecutables directamente desde la consola, todo en la misma plataforma.
Si quieres ver cómo se ve eso en la práctica, tienes 2 semanas de prueba gratuita para comprobarlo.
Lecturas relacionadas para seguir
Si quieres aterrizar este tema en una operación real, sigue con estas guías: