El usuario llama. "La compu está rara." Tú preguntas qué tan rara. Silencio. "No sé, lenta o algo."
Sin monitoreo, ahí empieza una historia de media hora: conectarte, revisar, preguntar, descartar. Con monitoreo, muchas veces ya sabías que algo estaba mal antes de que te marcara.
Pero "monitoreo" abarca bastante. Aquí te explico qué significa a fondo: qué ves, qué dispara alertas, y cómo pasar de la detección a resolver sin improvisar.
1) Lo que el monitoreo te muestra en tiempo real
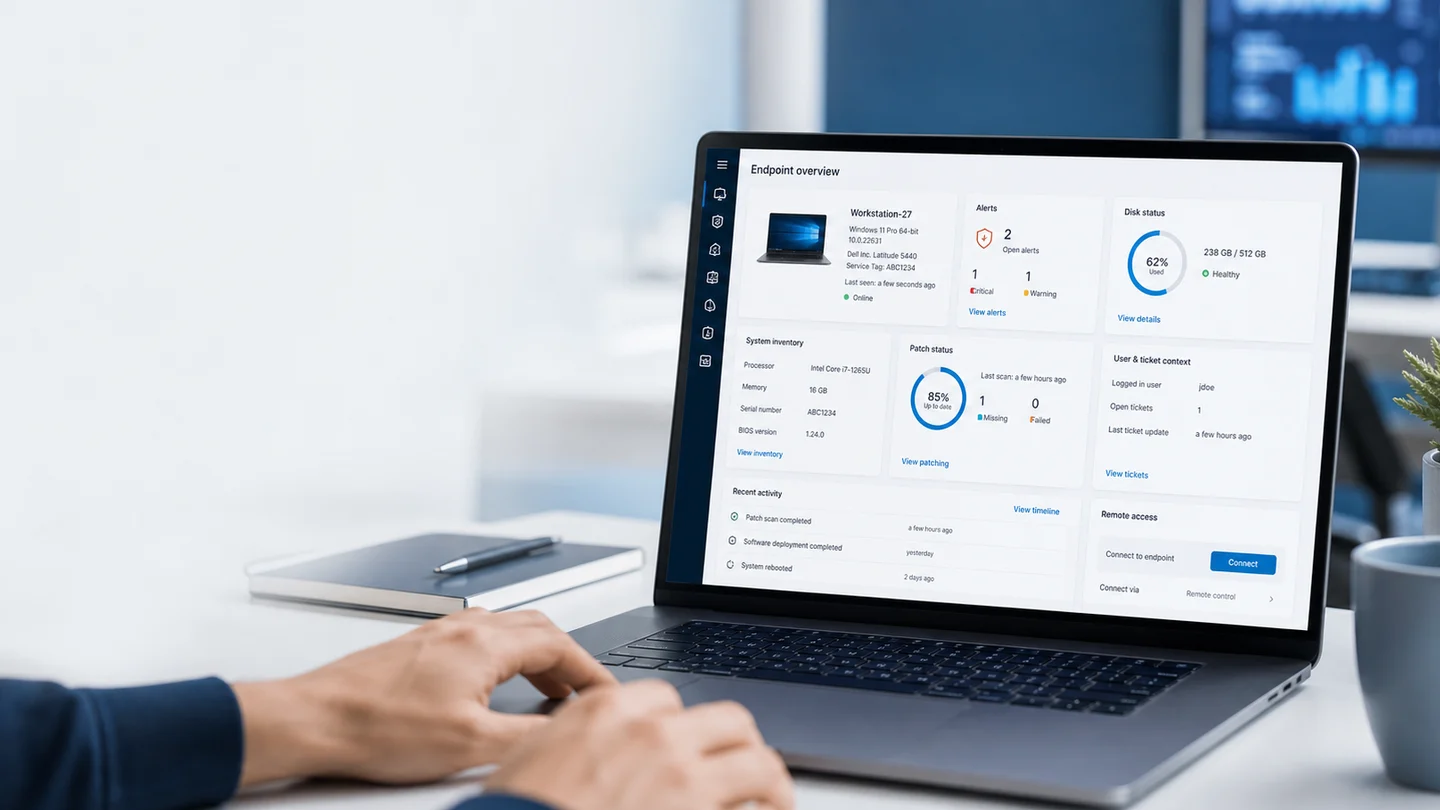
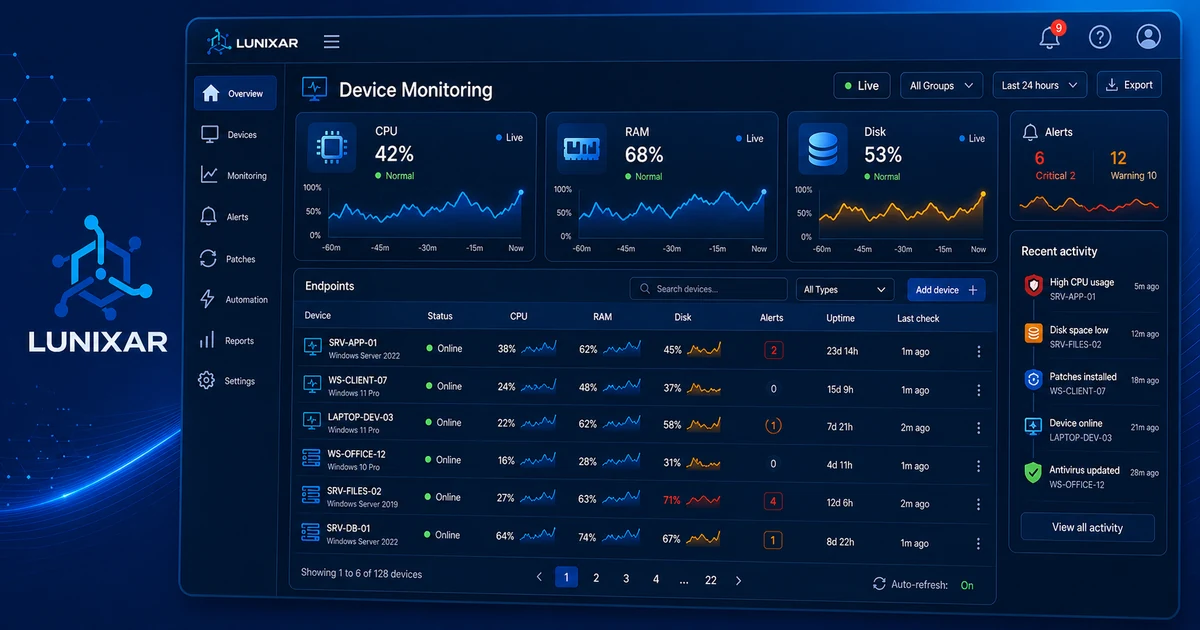
El estado de cada dispositivo administrado está visible en el portal: si está online, offline, con alertas activas, o sin actividad reciente.
Pero lo valioso está en el detalle:
- CPU y RAM: uso actual y tendencia evaluada en un período sostenido. No se alerta por un pico puntual, sino cuando el problema persiste.
- Disco: porcentaje ocupado por volumen, con alertas configurables antes de llegar al límite.
- Servicios Windows: cuáles están corriendo, cuáles se detuvieron, cuáles fallaron al reiniciar.
- Procesos activos: qué está consumiendo recursos en este momento.
- Última conexión del agente: para detectar equipos que perdieron contacto sin que nadie reportara nada.
2) Alertas de rendimiento: actúa antes de que explote
Las alertas no son para cuando ya falló. Son para cuando todavía puedes hacer algo.
Las más útiles en el día a día:
- LowDiskSpace: el clásico. Un equipo con disco al 95% no falla de golpe, pero sí te arruina la semana si lo ignoras.
- DiskSmartPredictedFailure: el disco está reportando errores internos. Esta alerta vale oro: te avisa de una falla de hardware antes de que ocurra. Tiempo para actuar = tiempo para respaldar.
- CPU y RAM sostenidos: si el uso se mantiene alto en un período, la alerta llega. No es un pico de dos segundos, es un proceso que se colgó o una aplicación que se escapó.
El valor aquí no es saber que algo falló. Es saber que algo está a punto de fallar.

3) Alertas de seguridad: lo que pasa sin que nadie te avise
Este grupo es el más crítico y el que con más frecuencia pasa desapercibido sin un RMM.
Alertas de antivirus y Defender:
AntivirusDisabled: alguien desactivó el antivirus. Puede ser un usuario, puede ser un malware.MalwareDetected: Defender encontró algo. La alerta llega antes de que el usuario te cuente (si es que te cuenta).DefenderExclusionAdded: se agregó una exclusión a Defender. En entornos no controlados, esto es señal de alerta.
Alertas de eventos de seguridad:
FailedLoginBurstyAccountLockoutBurst: múltiples intentos fallidos o cuentas bloqueadas en un período corto. Puede ser un usuario que olvidó su contraseña… o un ataque de fuerza bruta.SecurityLogCleared: el log de eventos de seguridad fue borrado. Pocas veces hay razón legítima para esto.PrivilegedGroupMembershipChange: alguien fue agregado a un grupo privilegiado (Administradores, por ejemplo).AuditPolicyChanged: se modificó la política de auditoría del sistema.
Estas últimas cuatro son el tipo de alerta que nadie ve hasta que hace una auditoría, si es que la hace.
4) Inventario y snapshots: el contexto que lo explica todo
El inventario de hardware y software se rastrea de forma independiente por dispositivo. No es una foto fija: se toman hasta 5 snapshots históricos por equipo, lo que te permite comparar antes y después de un incidente.
¿Para qué sirve en la práctica?
- Revisar qué software se instaló o desinstalió entre el snapshot anterior y hoy.
- Confirmar si los componentes de hardware cambiaron (RAM, disco, tarjeta de red).
- Verificar la versión del sistema operativo y si tiene actualizaciones pendientes.
- Tener contexto completo antes de abrir una sesión remota: qué equipo es, qué tiene, qué cambió.
Esto es especialmente útil cuando un usuario dice "antes funcionaba bien" y no sabe qué cambió. La respuesta casi siempre está en el inventario.
5) Acciones remotas sobre Defender: del monitoreo a la resolución
El monitoreo no termina en la alerta. Para dispositivos Windows, puedes actuar directamente sobre Windows Defender desde el portal:
- QuickScan: escaneo rápido de las áreas más comunes de infección.
- FullScan: escaneo completo del sistema.
- UpdateSignatures: actualizar las definiciones de virus sin intervención del usuario.
- RemoveThreats: eliminar amenazas detectadas que Defender ya identificó.
Estas acciones se pueden aplicar de forma individual o en toda la flota a la vez (bulk actions). Si recibes una alerta de MalwareDetected en varios equipos al mismo tiempo, no tienes que conectarte a cada uno: lanzas la acción desde el portal y los equipos la ejecutan.
Una nota importante: si el equipo usa un antivirus distinto a Windows Defender, el monitoreo muestra el estado de ese antivirus (activo/inactivo, última actualización), pero las acciones remotas solo están disponibles para Defender. Lo mismo aplica para Linux: los dispositivos Linux tienen inventario, pero no acciones remotas ni gestión de patches.
Cierre
El monitoreo de dispositivos no es una función extra. Es la diferencia entre operar reactivo (alguien te avisa, tú corres) y operar con control (tú ves el problema, actúas antes de que explote).
Con métricas en tiempo real, alertas de rendimiento y seguridad, historial de inventario y acciones sobre Defender desde el portal, el flujo cambia: menos llamadas de "la compu está rara", más intervenciones silenciosas que el usuario nunca nota porque el problema ya no llegó.
Lunixar RMM concentra todo esto en un mismo lugar: monitoreo, alertas, inventario y acciones remotas sin saltar entre herramientas. Si quieres ver cómo funciona en tu flota, la prueba de 2 semanas no requiere tarjeta de crédito.
Lecturas relacionadas para seguir
Si quieres aterrizar este tema en una operación real, sigue con estas guías: