Tienes backup.
Eso dice el checklist.
Pero cuando la base se cae, la pregunta real no es esa.
La pregunta es: ¿puedes restaurar?
Ahí cambia todo.
Respuesta directa: un backup de base de datos solo cuenta si puedes restaurarlo en un entorno separado, dentro del RPO/RTO acordado, validar que la aplicación abre y guardar evidencia del resultado. El archivo por sí solo no prueba recuperación.
Un archivo .bak, un dump, un snapshot o una carpeta en la nube no significan continuidad. Significan que existe una copia. La continuidad empieza cuando puedes convertir esa copia en una base usable, dentro de un tiempo aceptable, con evidencia de que funcionó.
Las fuentes técnicas dicen lo mismo desde distintos ángulos. Microsoft documenta flujos de backup y restore para SQL Server. PostgreSQL separa respaldo lógico, respaldo físico y recuperación continua con WAL. MySQL dedica una sección completa a backup y recuperación. Y NIST, en su guía de planeación de contingencia, trata la recuperación como parte de continuidad, no como una tarea aislada.
1) Define qué significa "recuperar" antes de respaldar
Un backup sin objetivo es una apuesta.
No basta con decir "lo hacemos diario". ¿Diario a qué hora? ¿Qué pasa si se pierde lo de la mañana? ¿Cuánto tiempo puede estar caída la operación? ¿Quién decide si se restaura?
Necesitas dos números básicos:
- RPO: cuánto dato puedes perder.
- RTO: cuánto tiempo puedes tardar en volver.
Si tu cliente factura todo el día en una base de datos, un backup nocturno puede dejar una ventana enorme de pérdida. Si el sistema solo se usa una vez por semana, quizá el riesgo es distinto.
2) Separa copia de recuperación
La copia es el archivo.
La recuperación es el proceso.
En SQL Server, por ejemplo, puedes tener respaldos completos, diferenciales y de log. En PostgreSQL, puedes combinar base backups con WAL para llegar a un punto específico. En MySQL, los binlogs pueden ser parte de una estrategia para recuperar cambios después de una copia base.
Pero ninguna de esas piezas sirve si no sabes la secuencia:
- dónde está la copia;
- qué versión del motor la puede leer;
- qué logs o archivos adicionales necesita;
- en qué servidor se va a restaurar;
- quién valida que la aplicación abre;
- qué evidencia queda.
3) No confíes en un backup que vive en el mismo servidor
Esto pasa mucho.
El job corre.
El archivo se genera.
Todo se ve bien.
Y el archivo queda en el mismo disco que se va a llenar, fallar o cifrar.
Un respaldo serio necesita separación. No siempre significa una arquitectura enorme. Puede empezar con una copia externa, una ubicación separada, permisos diferentes y una retención clara.
El punto es simple: si el servidor se pierde, el backup no debe perderse con él.
4) Valida el archivo, pero no te quedes ahí
Microsoft incluye RESTORE VERIFYONLY para SQL Server. Es útil porque ayuda a revisar que el conjunto de respaldo sea legible y parezca completo.
Pero no confundas eso con una restauración real.
Una verificación puede detectar problemas obvios. Una restauración de prueba detecta problemas operativos:
- el archivo tarda demasiado;
- falta un log;
- el usuario no tiene permisos;
- la versión del motor no coincide;
- la base restaura, pero la aplicación no conecta;
- el procedimiento no cabe en la ventana de recuperación.
En otras palabras: verificar ayuda. Restaurar comprueba.
5) Haz una prueba de restauración que deje evidencia
La prueba no necesita ser teatral.
Necesita ser repetible.
Un flujo mínimo se ve así:
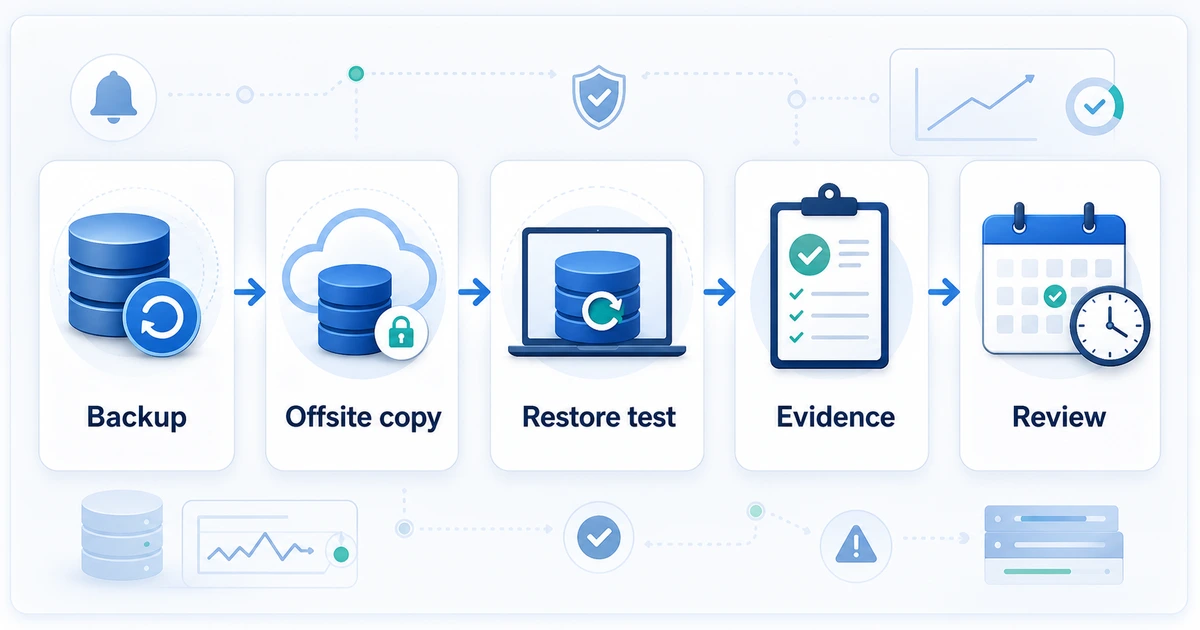
- Tomas el backup más reciente.
- Lo copias o lees desde la ubicación externa.
- Lo restauras en un entorno aislado.
- Corres una validación básica: tablas clave, conteos, login de aplicación o consulta crítica.
- Guardas evidencia: fecha, archivo usado, tiempo de restore, resultado, errores y responsable.
El objetivo no es llenar carpetas de PDFs. El objetivo es poder decir: "este backup fue restaurado el día X y tardó Y".
6) Monitorea las señales alrededor del backup
Lunixar RMM no reemplaza tu estrategia de backup.
Y no debería prometer eso.
Pero sí puede ayudar con señales que suelen romperla en silencio:
- poco espacio en disco antes de que el job falle;
- servicio crítico detenido;
- servidor offline;
- cambios de inventario que explican una falla;
- alertas de disco o salud del endpoint;
- evidencia operativa para reportes.
Eso conecta con monitoreo de dispositivos, alertas, inventario y reportes RMM para clientes y auditorías. El backup lo define tu política de datos. El monitoreo ayuda a que el flujo no falle sin que nadie se entere.
7) Reporta restauraciones, no solo respaldos
Un reporte que dice "backup exitoso" puede sonar bien.
Pero el cliente necesita entender si puede recuperar.
Mejor reporta:
- último backup generado;
- última copia externa confirmada;
- última restauración probada;
- tiempo real de restore;
- errores encontrados;
- riesgos pendientes;
- próxima prueba programada.
Esto cambia la conversación. Ya no es "sí, se respaldó". Es "sí, se restauró en 38 minutos y falta reducir la ventana de pérdida en esta base".
8) Checklist mínimo para tu próxima revisión
Usa esto como punto de partida:
- ¿Qué bases existen y quién las usa?
- ¿Cuál es el RPO y RTO de cada una?
- ¿Qué tipo de backup se ejecuta?
- ¿Dónde queda la copia primaria?
- ¿Existe copia externa?
- ¿Cuántos días de retención tienes?
- ¿Quién recibe alertas de falla?
- ¿Cuándo fue la última restauración de prueba?
- ¿Cuánto tardó?
- ¿Qué evidencia quedó?
Si no puedes responder esas preguntas, el problema no es solo técnico. Es operativo.
FAQ: backups de bases de datos y pruebas de restauración
¿Cada cuánto debo probar la restauración de una base de datos?
Depende de la criticidad del sistema, pero una base importante debería tener pruebas periódicas y evidencia reciente. Para clientes pequeños, una revisión mensual o trimestral suele ser un punto de partida más realista que esperar al día del incidente.
¿Un RESTORE VERIFYONLY o una verificación automática sustituyen una restauración?
No. Ayudan a detectar problemas de lectura o consistencia del archivo, pero no prueban todo el flujo operativo. Una restauración real valida permisos, versión del motor, tiempo de recuperación, conexión de la aplicación y evidencia.
¿Qué evidencia debería guardar después de una prueba?
Guarda fecha, base probada, archivo usado, ubicación de origen, destino de restauración, duración, resultado, errores, responsable y siguiente acción. Esa evidencia convierte el backup en una conversación operativa, no solo en una casilla marcada.
¿Qué pasa si el backup está en el mismo servidor de producción?
Tienes una copia frágil. Si el servidor falla, se cifra, se llena o se pierde, el respaldo puede perderse junto con producción. Como mínimo, separa ubicación, permisos, retención y acceso administrativo.
¿Lunixar RMM reemplaza una herramienta de backup?
No. Lunixar RMM no reemplaza tu motor de base de datos ni tu herramienta de backup. Sirve para acompañar la operación con monitoreo, alertas, inventario y reportes que ayudan a detectar señales alrededor del proceso.
Tu backup no cuenta hasta que lo restauras
Tener respaldo es el inicio.
Restaurar es la prueba.
Y documentar es lo que convierte esa prueba en confianza.
Si administras clientes, no vendas tranquilidad basada en archivos que nadie ha probado. Construye una rutina: backup, copia externa, restore test, evidencia y revisión.
Con Lunixar RMM para MSPs puedes acompañar esa rutina con monitoreo, alertas, inventario y reportes operativos. No sustituye tu motor de base de datos ni tu herramienta de backup. Te ayuda a ver señales, mantener seguimiento y entregar evidencia antes de que el problema se vuelva incendio.
Para conectar este tema con tu operación diaria, revisa también primera política de alertas RMM y monitoreo de dispositivos a fondo.