Você tem backup.
O checklist diz isso.
Mas quando o banco cai, essa não é a pergunta real.
A pergunta real é: você consegue restaurar?
Aí muda tudo.
Resposta direta: um backup de banco de dados só conta se você consegue restaurá-lo em um ambiente separado, cumprir o RPO/RTO acordado, validar que a aplicação abre e guardar evidência do resultado. O arquivo sozinho não prova recuperação.
Um arquivo .bak, um dump, um snapshot ou uma pasta na nuvem não significa recuperação. Significa que existe uma cópia. A recuperação começa quando você consegue transformar essa cópia em um banco utilizável, dentro de um tempo aceitável, com evidência de que funcionou.
As fontes técnicas dizem isso por caminhos diferentes. A Microsoft documenta backup e restore no SQL Server. O PostgreSQL separa backups lógicos, físicos e arquivamento contínuo com WAL. O MySQL tem uma seção inteira sobre backup e recuperação. E o NIST, no guia de planejamento de contingência, trata recuperação como parte de continuidade, não como tarefa técnica isolada.
1) Defina o que significa "recuperar" antes de fazer backup
Backup sem objetivo é aposta.
Não basta dizer "fazemos todo dia". Todo dia em que horário? O que acontece se você perder o trabalho da manhã? Quanto tempo a operação pode ficar parada? Quem decide se restaura?
Você precisa de dois números básicos:
- RPO: quanto dado você pode perder.
- RTO: quanto tempo a recuperação pode levar.
Se o cliente fatura o dia inteiro em um banco, um backup noturno pode deixar uma janela grande de perda. Se o sistema é usado uma vez por semana, o risco muda.
2) Separe cópia de recuperação
A cópia é o arquivo.
A recuperação é o processo.
No SQL Server, por exemplo, você pode ter backups completos, diferenciais e de log. No PostgreSQL, pode combinar base backups com WAL para chegar a um ponto específico no tempo. No MySQL, binlogs podem fazer parte da recuperação de mudanças depois de uma cópia base.
Mas nenhuma dessas peças ajuda se você não sabe a sequência:
- onde a cópia está;
- qual versão do motor consegue lê-la;
- quais logs ou arquivos adicionais ela precisa;
- em qual servidor será restaurada;
- quem valida que a aplicação abre;
- qual evidência fica salva.
3) Não confie em um backup que vive no mesmo servidor
Isso acontece muito.
O job roda.
O arquivo é criado.
Tudo parece certo.
E o arquivo fica no mesmo disco que pode encher, falhar ou ser criptografado.
Um backup sério precisa de separação. Isso nem sempre exige uma arquitetura enorme. Pode começar com uma cópia externa, um local separado, permissões diferentes e retenção clara.
O ponto é simples: se o servidor for perdido, o backup não deve ser perdido junto com ele.
4) Valide o arquivo, mas não pare aí
A Microsoft inclui RESTORE VERIFYONLY no SQL Server. Ele é útil porque ajuda a revisar se o conjunto de backup está legível e parece completo.
Mas não confunda isso com uma restauração real.
Uma verificação pode detectar problemas óbvios. Uma restauração de teste detecta problemas operacionais:
- o arquivo demora demais;
- falta um log;
- o usuário não tem permissão;
- a versão do motor não bate;
- o banco restaura, mas a aplicação não conecta;
- o processo não cabe na janela de recuperação.
Em resumo: verificar ajuda. Restaurar comprova.
5) Faça uma restauração de teste que deixe evidência
O teste não precisa ser teatral.
Precisa ser repetível.
Um fluxo mínimo fica assim:
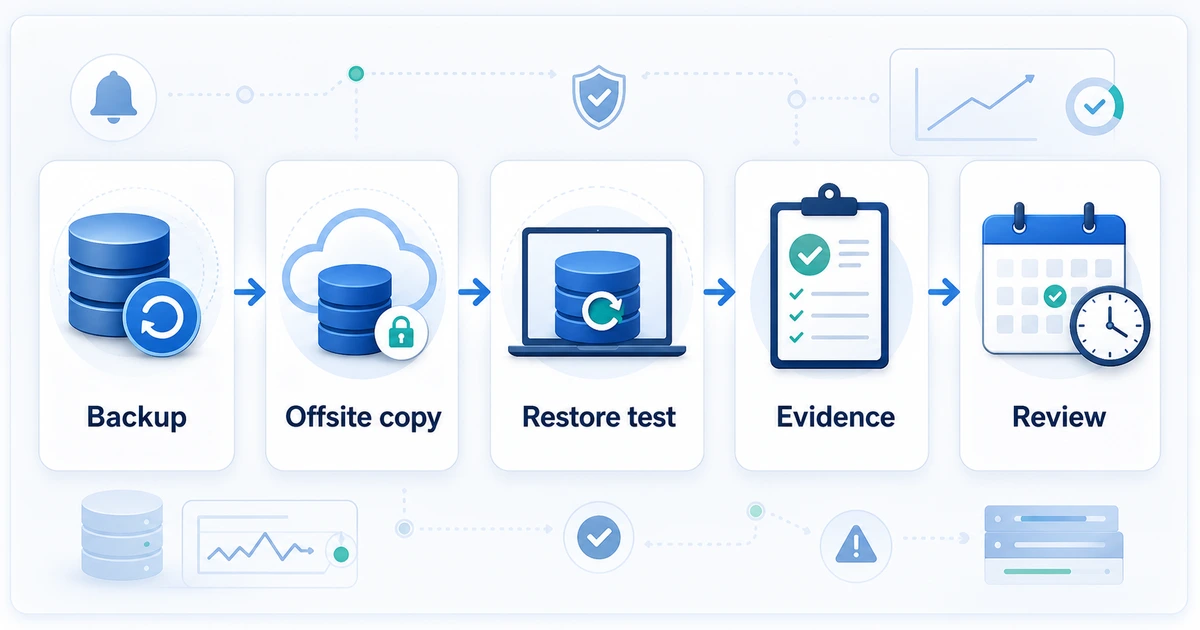
- Usa o backup mais recente.
- Lê ou copia a partir da localização externa.
- Restaura em um ambiente isolado.
- Roda uma validação básica: tabelas-chave, contagens, login da aplicação ou consulta crítica.
- Salva evidência: data, arquivo usado, tempo de restore, resultado, erros e responsável.
O objetivo não é encher pastas de PDFs. O objetivo é poder dizer: "este backup foi restaurado nesta data e levou este tempo".
6) Monitore os sinais ao redor do backup
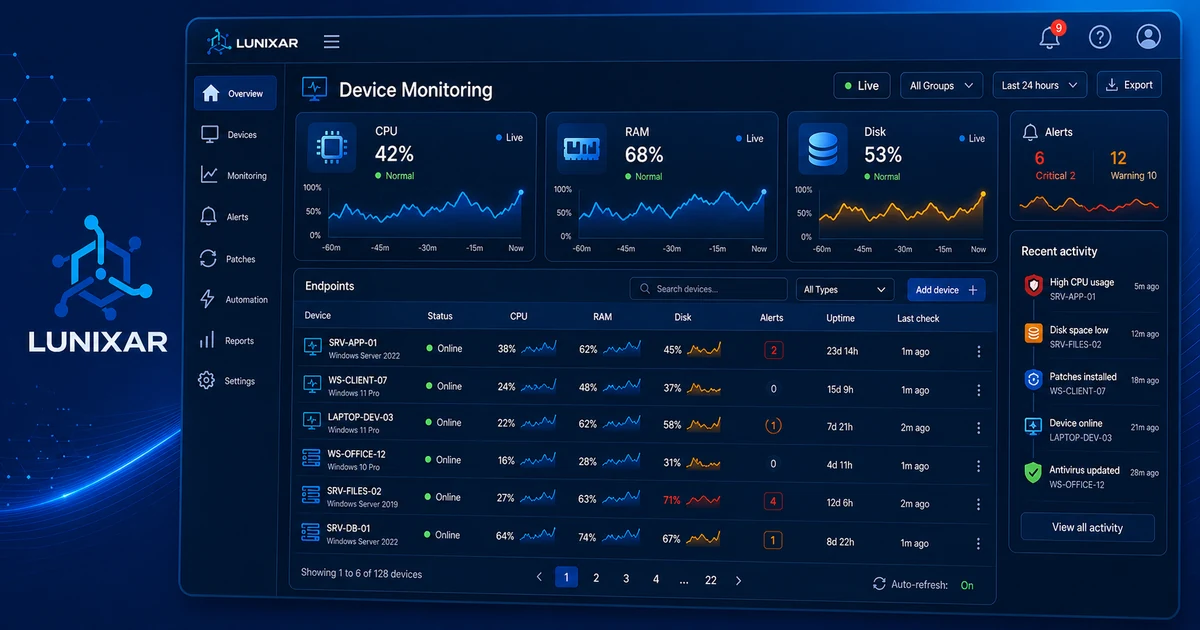
Lunixar RMM não substitui sua estratégia de backup de banco de dados.
E não deveria fingir que substitui.
Mas pode ajudar com sinais que costumam quebrar rotinas de backup em silêncio:
- pouco espaço em disco antes do job falhar;
- serviço crítico parado;
- servidor offline;
- mudanças de inventário que explicam uma falha;
- alertas de disco ou saúde do endpoint;
- evidência operacional para relatórios.
Isso se conecta com monitoramento de dispositivos, alertas, inventário e relatórios RMM para clientes e auditorias. A política de dados define o backup. O monitoramento ajuda o fluxo a não falhar em silêncio.
7) Relate restaurações, não apenas backups
Um relatório que diz "backup com sucesso" soa bem.
Mas o cliente precisa entender se consegue recuperar.
Relate sinais melhores:
- último backup gerado;
- última cópia externa confirmada;
- última restauração testada;
- tempo real de restore;
- erros encontrados;
- riscos pendentes;
- próximo teste agendado.
Isso muda a conversa. Não é mais "sim, fez backup". É "sim, restaurou em 38 minutos, e ainda precisamos reduzir a janela de perda neste banco".
8) Checklist mínimo para sua próxima revisão
Use isto como ponto de partida:
- Quais bancos existem e quem usa?
- Qual é o RPO e RTO de cada um?
- Que tipo de backup roda?
- Onde fica a cópia primária?
- Existe cópia externa?
- Quantos dias de retenção você mantém?
- Quem recebe alertas de falha?
- Quando foi a última restauração de teste?
- Quanto tempo levou?
- Que evidência ficou salva?
Se você não consegue responder essas perguntas, o problema não é apenas técnico. É operacional.
FAQ: backups de bancos de dados e testes de restauração
Com que frequência devo testar a restauração de um banco de dados?
Depende da criticidade do sistema, mas um banco importante deve ter testes periódicos e evidência recente. Para clientes pequenos, uma validação mensal ou trimestral costuma ser mais realista do que esperar o dia do incidente.
RESTORE VERIFYONLY ou uma verificação automática substituem uma restauração?
Não. A verificação pode detectar problemas de leitura ou consistência do arquivo, mas não prova todo o fluxo operacional. Uma restauração real valida permissões, versão do motor, tempo de recuperação, conexão da aplicação e evidência.
Que evidência devo guardar depois de um teste?
Guarde data, banco testado, arquivo usado, localização de origem, destino da restauração, duração, resultado, erros, responsável e próxima ação. Essa evidência transforma status de backup em conversa operacional, não apenas em checklist.
E se o backup estiver no mesmo servidor de produção?
Você tem uma cópia frágil. Se o servidor falhar, for criptografado, encher ou se perder, o backup pode se perder junto com produção. No mínimo, separe localização, permissões, retenção e acesso administrativo.
Lunixar RMM substitui uma ferramenta de backup?
Não. Lunixar RMM não substitui seu motor de banco de dados nem sua ferramenta de backup. Ele acompanha a operação com monitoramento, alertas, inventário e relatórios que ajudam a detectar sinais ao redor do processo.
Seu backup não conta até você restaurar
Ter backup é o início.
Restaurar é a prova.
Documentar é o que transforma essa prova em confiança.
Se você administra clientes, não venda tranquilidade baseada em arquivos que ninguém testou. Crie uma rotina: backup, cópia externa, teste de restauração, evidência e revisão.
Com Lunixar RMM para MSPs, você pode acompanhar essa rotina com monitoramento, alertas, inventário e relatórios operacionais. Ele não substitui seu motor de banco de dados nem sua ferramenta de backup. Ele ajuda você a ver sinais, manter acompanhamento e entregar evidência antes que o problema vire incêndio.
Para conectar este tema com a operação diária, veja também primeira política de alertas RMM e monitoramento de dispositivos a fundo.