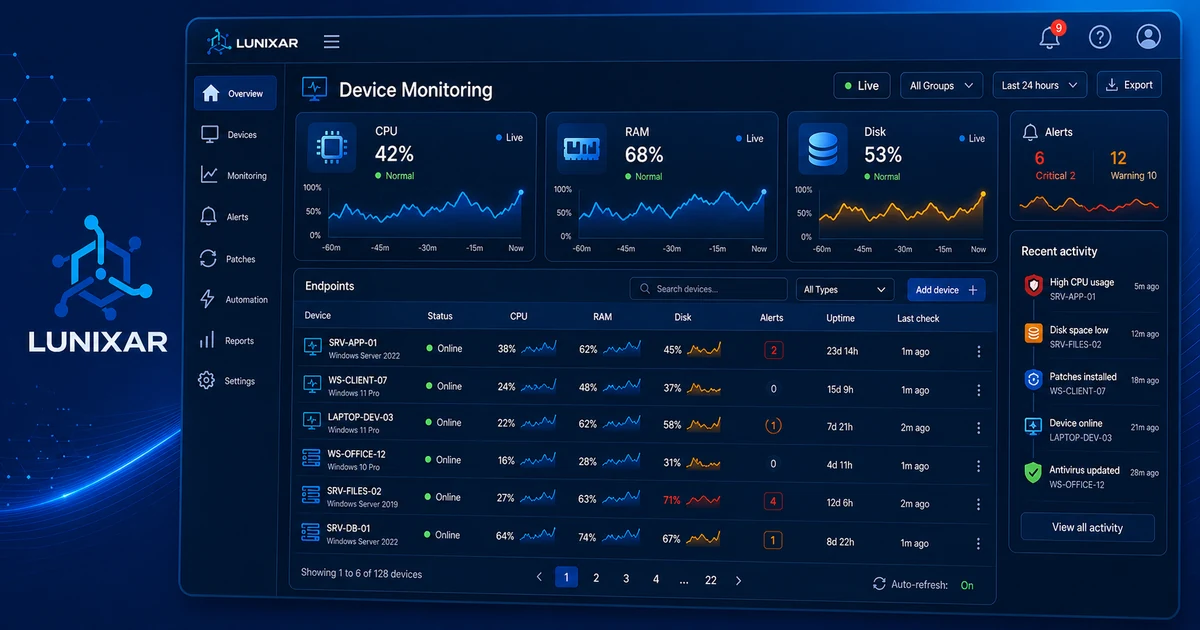
Hay alertas que te salvan el día.
Y alertas que solo hacen ruido.
La diferencia está en la política.
Si estás empezando con RMM, no intentes prender todas las notificaciones desde el primer día. Empieza con una política operativa pequeña: qué señales importan, quién las atiende, cuándo escalan y qué evidencia debe quedar.

1) Empieza con pocas alertas, pero que sí duelan
La tentación es obvia: "alertemos todo".
CPU, RAM, disco, antivirus, usuarios, sesiones, parches, servicios, cualquier cambio. Suena completo... hasta que llegan 80 correos y nadie lee el número 81.
Para una primera política, elige señales que tengan acción clara:
LowDiskSpace: todavía puedes liberar espacio antes de que la compu se vuelva inútil.DiskSmartPredictedFailure: tienes una ventana para respaldar o reemplazar disco.AntivirusDisabled: un endpoint Windows perdió una protección básica.MalwareDetected: Defender encontró algo y necesitas revisar contexto.FailedLoginBurstoAccountLockoutBurst: puede ser error de usuario, pero también puede ser fuerza bruta o credenciales mal usadas.
No estás buscando perfección. Estás buscando señales que muevan a alguien a hacer algo.
2) Separa seguridad, continuidad y mantenimiento
No todas las alertas van al mismo carril.
Una alerta de malware no se trata igual que disco bajo. Una ráfaga de logins fallidos no tiene la misma urgencia que un endpoint offline que ya sabías que estaba apagado.
Divide tu primera política en tres grupos:
| Grupo | Ejemplos | Respuesta esperada |
|---|---|---|
| Seguridad | MalwareDetected, AntivirusDisabled, SecurityLogCleared, PrivilegedGroupMembershipChange | Revisar contexto, ejecutar acción de seguridad y documentar |
| Continuidad | DiskSmartPredictedFailure, endpoint crítico offline, disco lleno | Evitar caída, respaldar, liberar espacio o reemplazar |
| Mantenimiento | parches pendientes, inventario desactualizado, cambios esperados | Programar seguimiento sin interrumpir lo urgente |
Seguridad
MalwareDetected, AntivirusDisabled, SecurityLogCleared, PrivilegedGroupMembershipChange
Revisar contexto, ejecutar acción de seguridad y documentar
Continuidad
DiskSmartPredictedFailure, endpoint crítico offline, disco lleno
Evitar caída, respaldar, liberar espacio o reemplazar
Mantenimiento
parches pendientes, inventario desactualizado, cambios esperados
Programar seguimiento sin interrumpir lo urgente
Este orden ayuda a que el técnico no brinque de una alerta menor a una señal crítica como si fueran iguales.
3) Define cuándo escalar antes de que llegue el incendio
Una alerta aislada puede esperar.
Un patrón no.
Por ejemplo: un login fallido en una laptop puede ser un dedo torpe. Una ráfaga de fallos en una cuenta privilegiada, seguida de bloqueo, ya merece otra lectura. Lo mismo con disco: 18% libre quizá no urge, pero 6% en un servidor de facturación un lunes a las 9:00 sí te va a cobrar factura.
Tu política debe decir:
- qué alertas atiende el técnico de primera línea;
- qué alertas escalan al responsable del cliente;
- qué alertas requieren acción inmediata;
- cuándo se crea ticket;
- cuándo se informa al cliente;
- qué se documenta al cerrar.
Como referencia externa, las guías de CISA Cybersecurity Performance Goals recomiendan mantener capacidad de detección, monitoreo y reporte para amenazas relevantes. NIST SP 800-61 Rev. 3 también trata la respuesta a incidentes como un ciclo preparado, no como improvisación.
4) Conecta alerta con contexto, no solo con correo
El correo te avisa.
Pero no resuelve.
Cuando llega una alerta, el técnico necesita contexto rápido:
- qué endpoint es;
- qué usuario lo usa;
- qué alertas recientes tiene;
- qué software e inventario tiene;
- qué parches están pendientes;
- si el problema ya pasó antes;
- qué acción se ejecutó la última vez.
Ese contexto vive mejor cerca de monitoreo de dispositivos, alertas, inventario y gestión de parches. Si cada dato vive en una herramienta distinta, el técnico pierde minutos reconstruyendo la historia.
5) En Windows, decide qué acción sigue
Una buena política no termina en "recibimos una alerta".
Termina en acción.
En endpoints Windows con Defender, Lunixar RMM puede ayudarte a pasar de señal a respuesta con acciones como UpdateSignatures, QuickScan, FullScan y RemoveThreats cuando aplica. Microsoft documenta que los quick scans de Defender suelen ser la opción recomendada para revisiones programadas u on-demand en la mayoría de los casos, junto con protección en tiempo real.
Eso no significa que cada alerta necesita un full scan. Significa que tu política debe decidir por gravedad:
AntivirusDisabled: revisar estado y restaurar protección.MalwareDetected: actualizar firmas, revisar detalle y ejecutar scan según el caso.DefenderExclusionAdded: validar si la exclusión fue autorizada.SecurityLogCleared: tratar como señal sensible y revisar quién hizo el cambio.
Para Linux, mantén la expectativa correcta dentro de este flujo: inventario y visibilidad de seguridad, no acciones remotas de Defender. La gestión de parches de Linux vive en el módulo de parches, no en las acciones de seguridad de Defender.
6) Usa una política mínima que cualquiera pueda seguir
La política no sirve si solo vive en la cabeza del técnico senior.
Tiene que ser visible, corta y repetible.
Una primera versión puede verse así:
| Alerta | Severidad inicial | Dueño | Tiempo de respuesta | Acción esperada | Evidencia de cierre |
|---|---|---|---|---|---|
MalwareDetected | Crítica | Seguridad / técnico senior | Hoy | Actualizar firmas, revisar detalle y ejecutar scan según gravedad | Resultado del scan y acción tomada |
AntivirusDisabled | Alta | Técnico asignado | Hoy | Validar estado y restaurar protección | Estado final del antivirus |
DiskSmartPredictedFailure | Alta | Técnico asignado | 24 horas | Respaldar, revisar reemplazo y avisar al cliente | Plan de reemplazo o mitigación |
LowDiskSpace | Media | Primera línea | 48 horas | Liberar espacio o programar limpieza | Espacio recuperado y causa probable |
FailedLoginBurst | Alta si afecta cuenta crítica | Seguridad / responsable del cliente | Hoy | Revisar cuenta, origen y patrón | Cuenta revisada y siguiente paso |
MalwareDetected
Crítica
Seguridad / técnico senior
Hoy
Actualizar firmas, revisar detalle y ejecutar scan según gravedad
Resultado del scan y acción tomada
AntivirusDisabled
Alta
Técnico asignado
Hoy
Validar estado y restaurar protección
Estado final del antivirus
DiskSmartPredictedFailure
Alta
Técnico asignado
24 horas
Respaldar, revisar reemplazo y avisar al cliente
Plan de reemplazo o mitigación
LowDiskSpace
Media
Primera línea
48 horas
Liberar espacio o programar limpieza
Espacio recuperado y causa probable
FailedLoginBurst
Alta si afecta cuenta crítica
Seguridad / responsable del cliente
Hoy
Revisar cuenta, origen y patrón
Cuenta revisada y siguiente paso
No necesitas que sea perfecta. Necesitas que evite la improvisación.
Plantilla rápida para tu política de alertas RMM
Copia esta estructura y adáptala por cliente:
``text Si aparece [alerta] en [tipo de endpoint], revisar [contexto mínimo], ejecutar [acción esperada], crear ticket si [condición], escalar a [responsable] si [condición], cerrar solo cuando quede documentado [resultado]. ``
Ejemplo:
``text Si aparece AntivirusDisabled en un servidor Windows, revisar estado de Defender y alertas recientes, restaurar protección y ejecutar UpdateSignatures, crear ticket si la protección no vuelve a estado normal, escalar al responsable del cliente si coincide con MalwareDetected, cerrar solo cuando quede documentado el estado final del antivirus. ``
FAQ: primera política de alertas RMM
¿Qué alertas debo activar primero en un RMM?
Empieza por alertas que tienen acción clara: LowDiskSpace, DiskSmartPredictedFailure, AntivirusDisabled, MalwareDetected, FailedLoginBurst y AccountLockoutBurst. Después agrega señales según el tipo de cliente y criticidad de endpoints.
¿Cómo evito demasiadas alertas?
No actives alertas sin dueño, severidad y acción esperada. Si una alerta no cambia una decisión, probablemente solo agrega ruido. Revisa semanalmente qué alertas fueron útiles y cuáles nadie atendió.
¿Cada alerta debe crear un ticket?
No. Algunas alertas solo necesitan revisión o cierre rápido. Crea ticket cuando requiere seguimiento, autorización, comunicación con cliente, evidencia o varias acciones. Si todo crea ticket, el tablero se vuelve otra bandeja de entrada.
¿Qué alertas son críticas para MSPs?
Las críticas suelen ser las que afectan seguridad o continuidad: malware, antivirus desactivado, logs de seguridad borrados, cambios en grupos privilegiados, falla prevista de disco y ráfagas de login en cuentas sensibles.
¿Cada cliente necesita la misma política?
No. Puedes empezar con una base común, pero servidores, equipos administrativos, puntos de venta y laptops de usuarios no tienen el mismo impacto. La política debe ajustarse por criticidad.
Cierra el ciclo: menos alertas, mejores decisiones
La primera política de alertas RMM no tiene que ser enorme.
Tiene que ser útil.
Empieza con señales de seguridad, continuidad y mantenimiento. Conecta cada alerta con contexto. Define quién responde. Documenta cierre. Ajusta cada semana.
Lunixar RMM encaja en ese flujo porque conecta monitoreo, alertas, inventario, parches, seguridad y acceso remoto en una misma operación. Si hoy tus alertas viven como correos sueltos, la prueba de 2 semanas te permite validarlo con hasta 5 dispositivos, sin tarjeta y con acceso completo.
También puedes seguir con estas guías: