La red siempre cuenta una historia.
El problema es que muchas veces nadie la está leyendo.
Tienes endpoints con agente, impresoras que solo aparecen cuando fallan, switches sin dueño claro, laptops invitadas, cámaras, access points, equipos apagados y dispositivos que "alguien conectó" sin avisar.
Eso no es un detalle menor. Lo que no está inventariado también consume red, genera tickets, crea riesgo y rompe la operación.

1) Empieza por contexto de red local
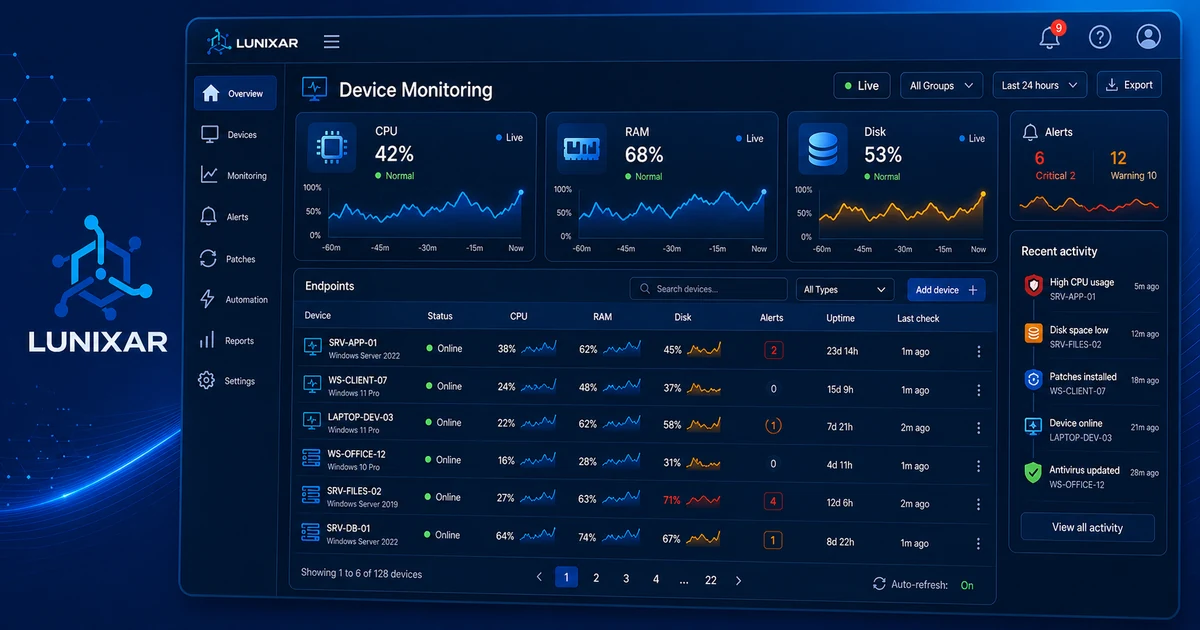
Un RMM no debería depender solo de los endpoints que ya tienen agente.
La pregunta correcta es:
¿qué más existe alrededor de mis endpoints administrados?
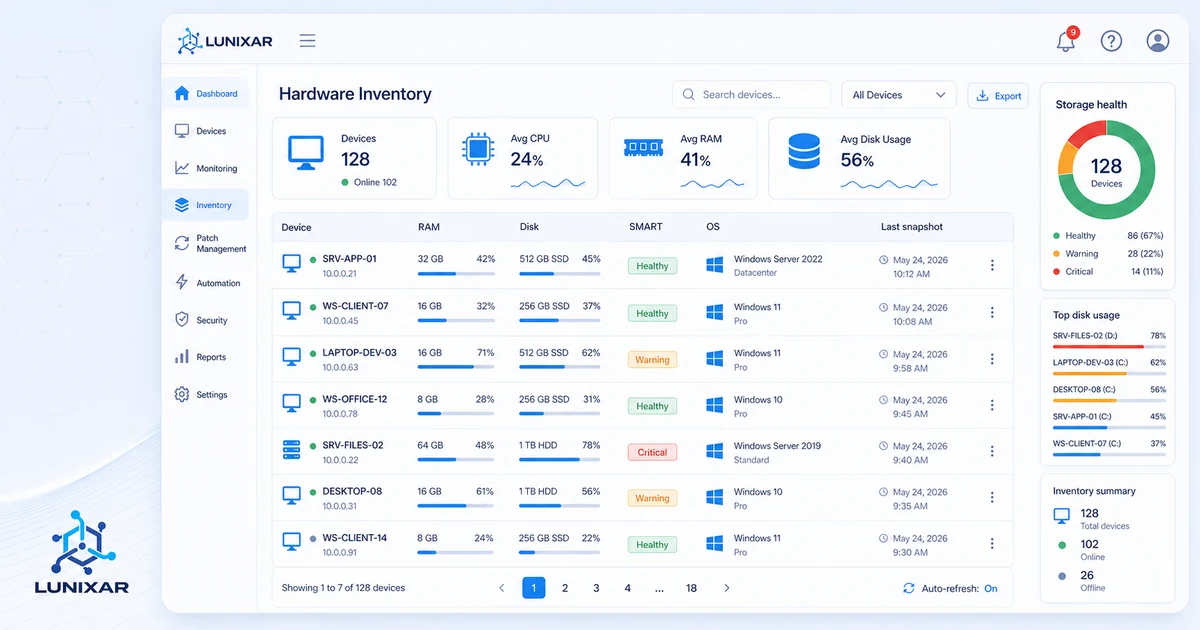
Para responder necesitas señales básicas de red: rango IP, dirección MAC, nombre detectado, fabricante probable, último visto, tipo de dispositivo y origen del descubrimiento. No es una CMDB perfecta desde el día uno. Es una vista práctica para dejar de operar a ciegas.
Ese contexto se conecta con monitoreo de dispositivos e inventario. Si un endpoint administrado está en una subred, el RMM puede ayudarte a revisar qué más vive cerca: impresoras, gateways, switches, access points o equipos sin agente.
2) Clasifica antes de decidir
No todo dispositivo descubierto pide la misma acción.
Una lista plana de IPs sirve poco. Lo útil es separar:
- Endpoint administrado: ya tiene agente, inventario y monitoreo.
- Endpoint conocido sin agente: debería evaluarse para enrolamiento.
- Infraestructura: router, switch, firewall, access point, impresora o NAS.
- Dispositivo temporal: visitante, equipo de prueba o hardware de reemplazo.
- Desconocido: requiere validación antes de ignorarlo.
Esa clasificación evita dos errores comunes: instalar agente donde no aplica y dejar sin seguimiento un equipo que sí debería estar administrado.
3) Usa SNMP v2c como snapshot, no como confianza ciega
SNMP puede dar contexto útil en infraestructura de red: interfaces, nombre de sistema, descripción, estado básico y ciertos contadores.
Pero SNMP v1/v2c usa comunidades compartidas, no un modelo moderno de autenticación fuerte. CISA recomienda administrar estos protocolos con cuidado, evitar valores por defecto y preferir configuraciones más seguras cuando estén disponibles.
Si tu operación todavía usa SNMP v2c para snapshots, úsalo con disciplina:
- solo lectura;
- comunidad no predeterminada;
- alcance limitado por segmento;
- consultas desde IPs de gestión autorizadas;
- rotación y documentación de credenciales;
- sin exponer SNMP fuera de redes administrativas.
El objetivo no es "confiar en SNMP". El objetivo es sumar una señal más para entender qué hay en la red y qué requiere seguimiento.
4) Convierte hallazgos en trabajo operativo
El descubrimiento de red no vale por la cantidad de dispositivos encontrados.
Vale por lo que haces después.
Un flujo sano se ve así:
- Detectar dispositivos en un segmento.
- Clasificar por tipo y confianza.
- Relacionar con cliente, sede o tenant.
- Asignar dueño o responsable técnico.
- Enrolar endpoints que sí deben tener agente.
- Monitorear infraestructura relevante.
- Marcar excepciones y dispositivos temporales.
Sin ese seguimiento, el descubrimiento se vuelve otra lista que nadie revisa.
5) Conecta red, inventario y alertas
Un dispositivo no administrado rara vez aparece solo.
Puede coincidir con un ticket de impresión, una caída de Wi-Fi, un cambio de gateway, un endpoint que cambió de subred o una alerta de disco en un servidor cercano.
Por eso el descubrimiento debe vivir cerca de:
- inventario de hardware y software;
- monitoreo de dispositivos;
- revisión semanal de la consola RMM;
- gestión de vulnerabilidades en RMM.
Cuando esas piezas se conectan, la conversación cambia. Ya no es "encontramos 43 IPs". Es "hay tres dispositivos sin dueño en la red del cliente, una impresora crítica sin monitoreo y dos laptops que deberían enrolarse".
6) Qué debería responder un RMM
Un buen flujo de descubrimiento de red debería responder rápido:
- qué segmentos se revisaron;
- qué dispositivos nuevos aparecieron;
- cuáles ya están administrados;
- cuáles son infraestructura;
- cuáles no tienen dueño;
- cuáles deberían enrolarse;
- cuándo fueron vistos por última vez;
- qué cambió desde el snapshot anterior.
Lunixar RMM conecta monitoreo, inventario y operación para que esa visibilidad no viva en hojas sueltas. La meta no es llenar un mapa bonito. La meta es reducir huecos: equipos sin agente, infraestructura sin seguimiento y cambios que nadie documentó.
Para evaluar el flujo completo, revisa monitoreo de dispositivos, inventario y Lunixar RMM para MSPs.