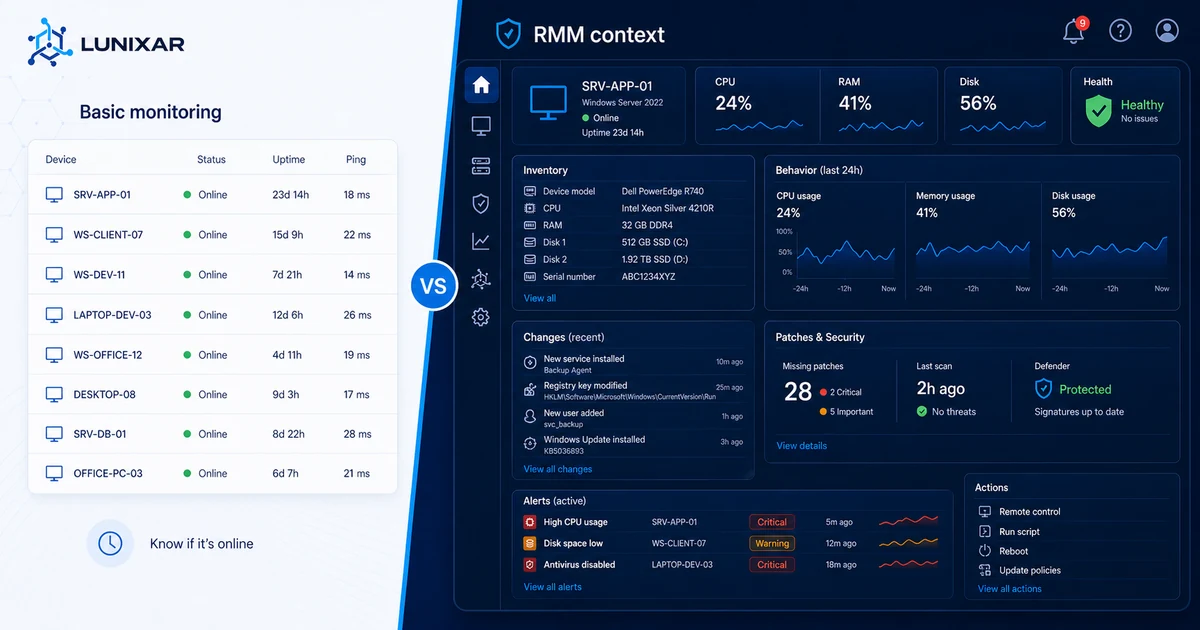
Se você usa Zabbix, PRTG, Nagios ou algum sistema de monitoramento básico, sabe que funciona.
Avisa quando um servidor cai. Mostra quando o disco está cheio. Dá um gráfico de uso de CPU ao longo do tempo.
E por um tempo, isso é suficiente.
Mas existe um momento — e a maioria dos MSPs e equipes de TI conhece bem — em que o alerta chega, você vê que "algo falhou", e ainda não sabe o que fazer, em qual equipamento exatamente, nem por que aconteceu.
É aí que o monitoramento básico chega no seu limite. E é aí que um RMM começa a fazer sentido.
1) O monitoramento básico diz que algo aconteceu. Um RMM diz o quê, por quê e em qual equipamento.
O monitoramento básico faz bem uma coisa: avisa quando algo cruza um limite.
CPU em 95% → alerta. Disco em 90% → alerta. Host sem resposta → alerta.
Mas o alerta é só o ponto de partida. O que vem depois — diagnosticar, entender o contexto, decidir o que fazer — está fora da ferramenta. Você precisa se conectar, vasculhar logs, verificar o que está rodando, perguntar ao usuário o que aconteceu.
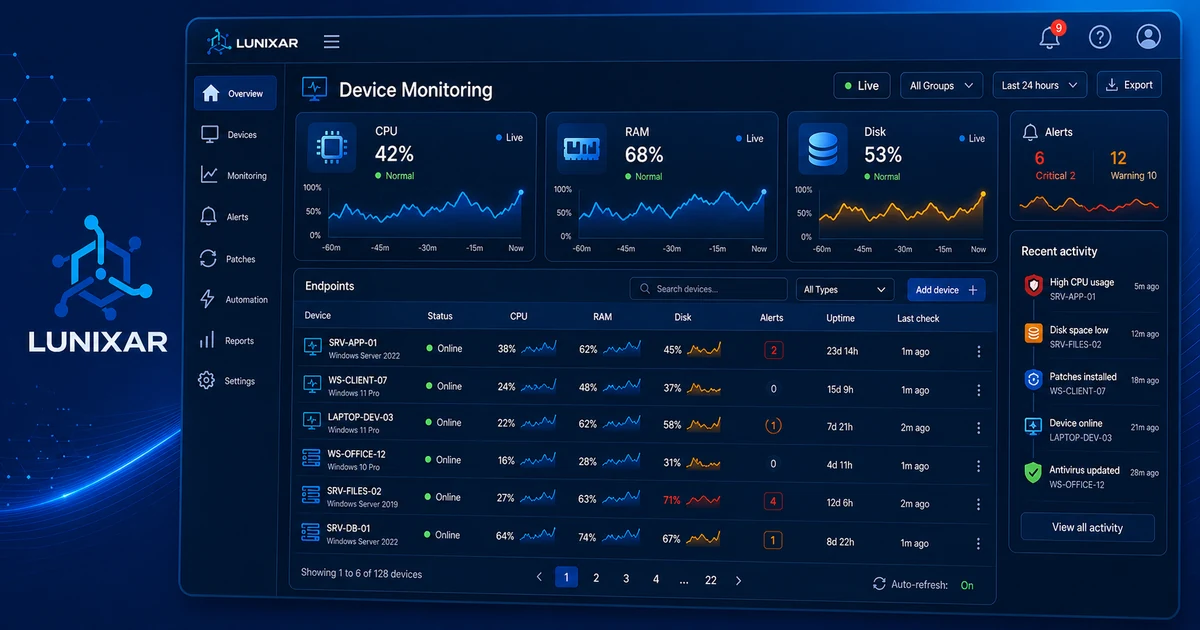
Com um RMM, esse contexto já está lá quando o alerta chega: qual software o equipamento tem instalado, o que mudou nos últimos dias, quanta memória livre havia antes do pico, se houve algum evento de sistema relacionado.
O monitoramento básico não está errado. Só chega até certo ponto e depois te deixa por conta.
2) O monitoramento básico não sabe o que tem instalado no equipamento
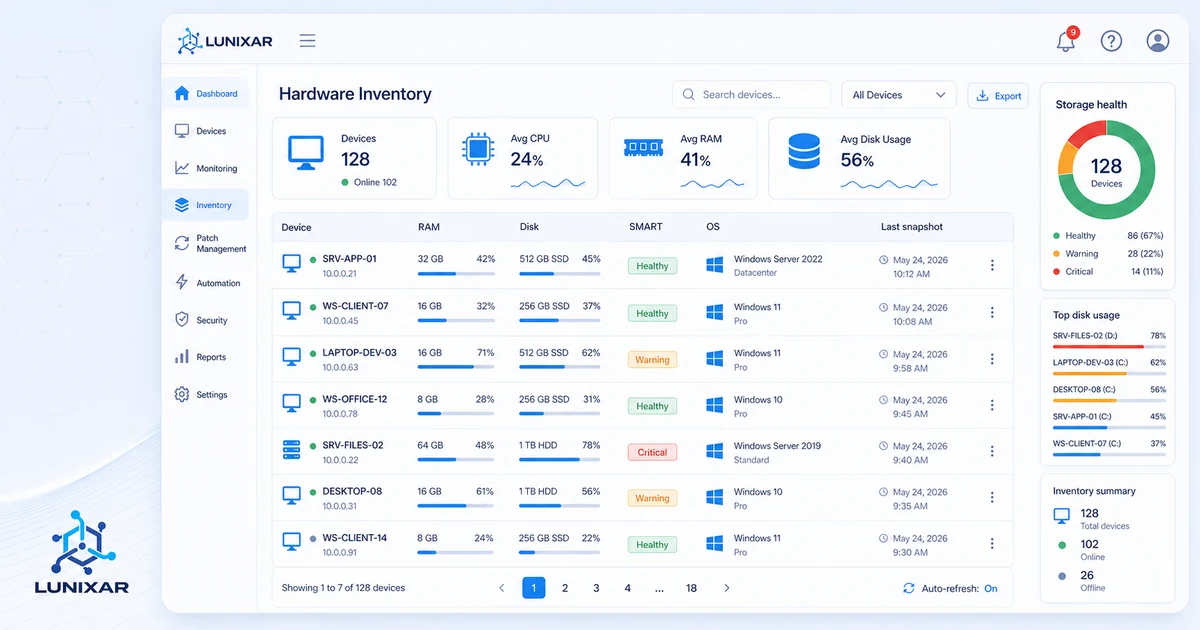
Uma das diferenças mais concretas: o inventário.
O monitoramento básico observa métricas. Um RMM conhece o equipamento.
Conhece qual software está instalado, em qual versão, qual hardware compõe a máquina, o que mudou nos últimos dias. Quando chega um alerta de CPU alta, você não precisa se conectar para investigar o que está causando — o contexto já está lá.
E quando um usuário reporta que "algo mudou" sem saber o quê, o histórico de snapshots responde em segundos.
Esse nível de conhecimento muda completamente como você trabalha: em vez de investigar do zero em cada chamado, você verifica hipóteses que já tem antes de abrir qualquer sessão.
3) Do "está fora" ao "já resolvi"
O monitoramento básico te notifica. Um RMM te deixa agir.
Essa diferença parece simples, mas muda todo o fluxo operacional.
Com monitoramento básico, o fluxo é: alerta → abre outra ferramenta → conecta remotamente → investiga → age. Vários passos, várias ferramentas, tempo perdido entre cada um.
Com um RMM, o fluxo pode ser: alerta → vê o contexto → executa a ação → resolvido. Tudo no mesmo console.
Não porque o RMM faz mágica — mas porque ele reúne visibilidade e capacidade de ação num só lugar. Isso reduz o tempo entre "fiquei sabendo" e "resolvi", que é exatamente o que separa o suporte proativo do reativo.
4) A proatividade que o monitoramento básico não consegue dar
O monitoramento básico é reativo por natureza. Espera algo cruzar um limite para avisar.
Um RMM bem configurado vai um passo antes: detecta tendências, não só leituras pontuais. Um disco que vem crescendo de forma anormal há duas semanas não precisa chegar em 95% para que alguém note. O comportamento já é o sinal.
O mesmo vale para hardware: os atributos SMART de um disco mostram se ele está começando a se degradar muito antes de falhar. Você só vê isso se tiver uma ferramenta analisando esses dados por você.
A diferença entre monitoramento e gestão proativa é a diferença entre saber que o tanque está vazio e saber que você está rodando no limite há três dias.
5) Quando o monitoramento básico já não é suficiente
O monitoramento básico funciona bem quando:
- Você tem poucos equipamentos e tempo para investigar cada alerta manualmente
- O equipamento que falha é fácil de identificar e acessar
- Você não precisa de rastreabilidade nem histórico de mudanças
- O suporte reativo está bem por enquanto
Começa a ser insuficiente quando:
- A frota cresce e você não consegue investigar manualmente cada alerta
- Os chamados aumentam mas o tempo não
- Você quer passar de reativo para proativo sem dobrar a equipe
- Você precisa de contexto antes de se conectar para não perder tempo
Não é que um seja categoricamente "melhor" que o outro. É que servem para momentos diferentes da operação.
Fechamento
O monitoramento básico é um bom ponto de partida. O problema é ficar nele por mais tempo do que o necessário.
Um RMM não substitui o monitoramento — estende com contexto, histórico e inventário, e adiciona a capacidade de agir sem trocar de ferramenta.
Lunixar RMM foi criado para tornar essa transição natural: alertas que chegam com contexto, inventário ativo por dispositivo e ações executáveis direto pelo console — tudo na mesma plataforma.
2 semanas de teste grátis. Sem cartão de crédito.
Leituras relacionadas para continuar
Se você quer levar este tema para uma operação real, continue com estes guias: