O usuário liga. "O computador está estranho." Você pergunta como assim. Silêncio. "Não sei, lento ou algo assim."
Sem monitoramento, esse é o começo de uma história de meia hora: conectar, investigar, perguntar, descartar. Com monitoramento, muitas vezes você já sabia que algo estava errado antes de ele ligar.
Mas "monitoramento" cobre bastante coisa. Aqui está o que significa na prática: o que você vê, o que dispara alertas e como passar da detecção para a resolução sem improvisar.
1) O que o monitoramento mostra em tempo real
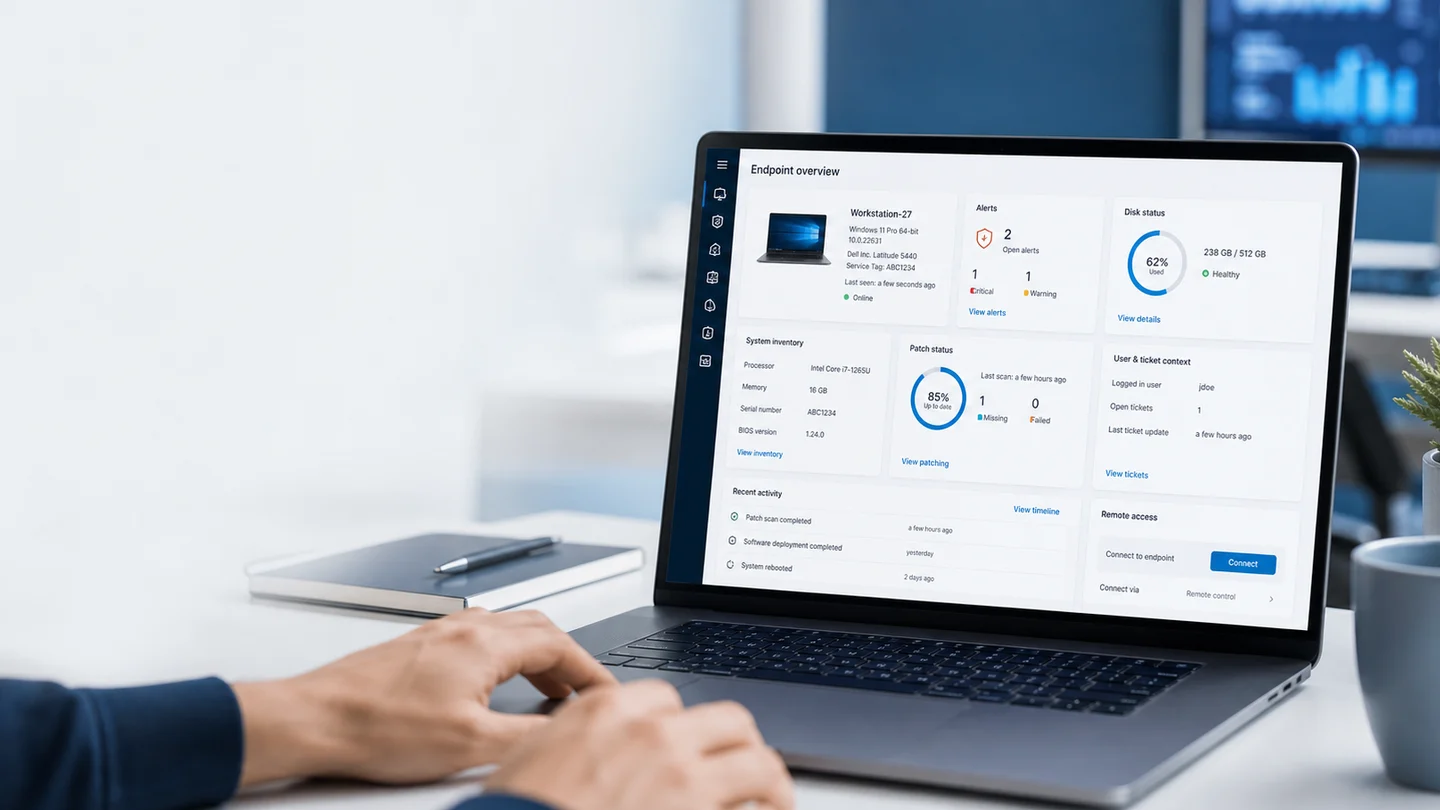
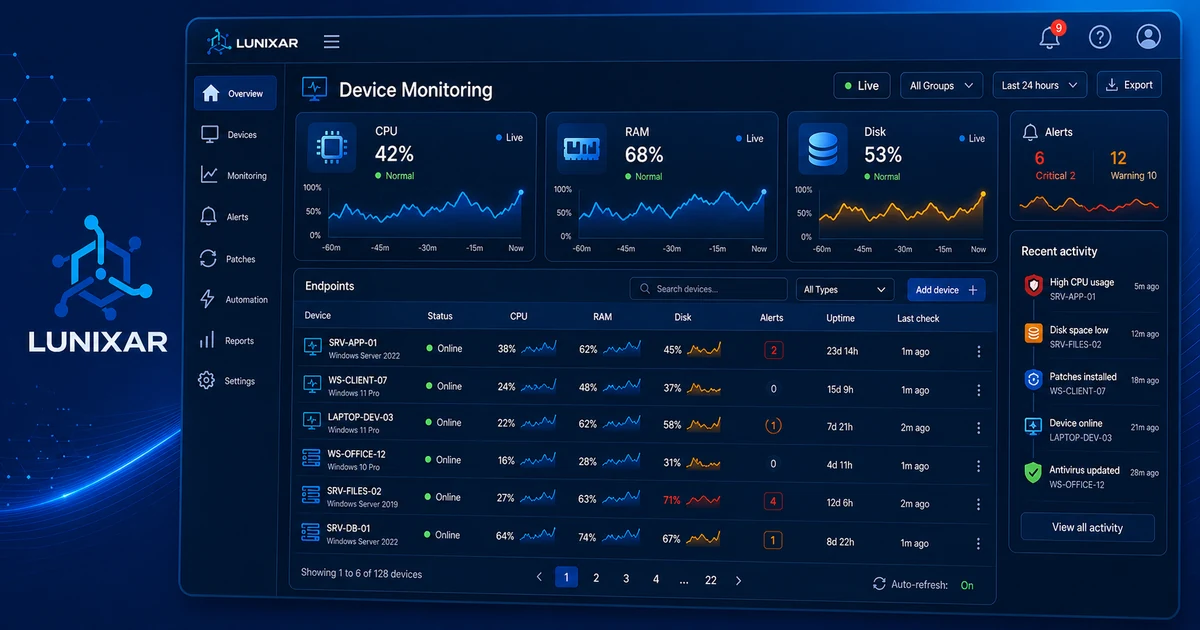
O estado de cada dispositivo gerenciado está visível no portal: online, offline, com alertas ativos ou sem atividade recente.
Mas o valor está no detalhe:
- CPU e RAM: uso atual e tendência avaliada ao longo de um período sustentado. Não alerta num pico momentâneo — alerta quando o problema persiste.
- Disco: porcentagem de uso por volume, com alertas configuráveis antes de atingir o limite.
- Serviços Windows: quais estão rodando, quais pararam, quais falharam ao reiniciar.
- Processos ativos: o que está consumindo recursos agora.
- Último contato do agente: para detectar dispositivos que perderam conexão antes de alguém reportar algo.
2) Alertas de desempenho: aja antes que exploda
Alertas não são para quando algo já quebrou. São para quando você ainda pode fazer algo.
Os mais úteis no dia a dia:
- LowDiskSpace: o clássico. Um dispositivo com 95% do disco cheio não falha de repente, mas vai arruinar sua semana se você ignorar.
- DiskSmartPredictedFailure: o disco está reportando erros internos. Esse alerta vale ouro — avisa de uma falha de hardware antes que aconteça. Tempo para agir = tempo para fazer backup.
- CPU e RAM sustentados: se o uso se mantiver alto ao longo de um período sustentado, o alerta dispara. Não é um pico de dois segundos — é um processo travado ou uma aplicação que fugiu do controle.
O valor aqui não é saber que algo falhou. É saber que algo está prestes a falhar.

3) Alertas de segurança: o que acontece sem ninguém te avisar
Esse grupo é o mais crítico — e o mais provável de passar despercebido sem um RMM.
Alertas de antivírus e Defender:
AntivirusDisabled: alguém desativou o antivírus. Pode ser um usuário, pode ser um malware.MalwareDetected: o Defender encontrou algo. O alerta chega antes de o usuário te contar (se é que conta).DefenderExclusionAdded: uma exclusão foi adicionada ao Defender. Em ambientes não controlados, isso é sinal de alerta.
Alertas de eventos de segurança:
FailedLoginBursteAccountLockoutBurst: múltiplas tentativas fracassadas ou contas bloqueadas em um curto período. Pode ser um usuário que esqueceu a senha… ou um ataque de força bruta.SecurityLogCleared: o log de eventos de segurança foi apagado. Raramente há motivo legítimo para isso.PrivilegedGroupMembershipChange: alguém foi adicionado a um grupo privilegiado (Administradores, por exemplo).AuditPolicyChanged: a política de auditoria do sistema foi modificada.
Esses quatro últimos são o tipo de alerta que ninguém vê até fazer uma auditoria — se é que faz.
4) Inventário e snapshots: o contexto que explica tudo
O inventário de hardware e software é rastreado de forma independente por dispositivo. Não é uma foto fixa: até 5 snapshots históricos por dispositivo são armazenados, permitindo comparar antes e depois de um incidente.
Para que serve na prática?
- Ver qual software foi instalado ou removido entre o snapshot anterior e hoje.
- Confirmar se os componentes de hardware mudaram (RAM, disco, placa de rede).
- Verificar a versão do sistema operacional e se há atualizações pendentes.
- Ter contexto completo antes de abrir uma sessão remota: que dispositivo é, o que tem, o que mudou.
Isso é especialmente útil quando um usuário diz "antes funcionava bem" e não sabe o que mudou. A resposta quase sempre está no inventário.
5) Ações remotas no Defender: do monitoramento à resolução
O monitoramento não termina no alerta. Para dispositivos Windows, você pode agir diretamente no Windows Defender a partir do portal:
- QuickScan: varredura rápida nas áreas de infecção mais comuns.
- FullScan: varredura completa do sistema.
- UpdateSignatures: atualizar as definições de vírus sem envolver o usuário.
- RemoveThreats: remover ameaças que o Defender já identificou.
Essas ações podem ser aplicadas individualmente ou em toda a frota de uma vez (ações em massa). Se chegar um alerta de MalwareDetected em vários dispositivos ao mesmo tempo, você não precisa se conectar a cada um — lança a ação no portal e os dispositivos a executam.
Uma nota importante: se o dispositivo usa um antivírus diferente do Windows Defender, o monitoramento mostra o status desse antivírus (ativo/inativo, última atualização), mas as ações remotas só estão disponíveis para o Defender. O mesmo vale para Linux: dispositivos Linux têm inventário, mas sem ações remotas e sem gerenciamento de patches.
Conclusão
O monitoramento de dispositivos não é uma função extra. É a diferença entre operar de forma reativa (alguém te avisa, você corre) e operar com controle (você vê o problema, age antes que exploda).
Com métricas em tempo real, alertas de desempenho e segurança, histórico de inventário e ações sobre o Defender a partir do portal, o fluxo muda: menos ligações sobre "o computador estar estranho", mais intervenções silenciosas que o usuário nunca percebe porque o problema nunca chegou.
Lunixar RMM reúne tudo isso em um só lugar: monitoramento, alertas, inventário e ações remotas sem saltar entre ferramentas. Se você quer ver como funciona na sua frota, o teste de 2 semanas não exige cartão de crédito.
Leituras relacionadas para continuar
Se você quer levar este tema para uma operação real, continue com estes guias: