
Hay parches que sí se instalan.
Y hay parches que quedan comprobados.
La diferencia se nota cuando algo falla, cuando un cliente pregunta, o cuando aparece una vulnerabilidad activa y necesitas saber qué equipos siguen expuestos.
Parchear bien no es dar clic en "actualizar". Es tener un flujo completo: detectar, priorizar, ejecutar y verificar.
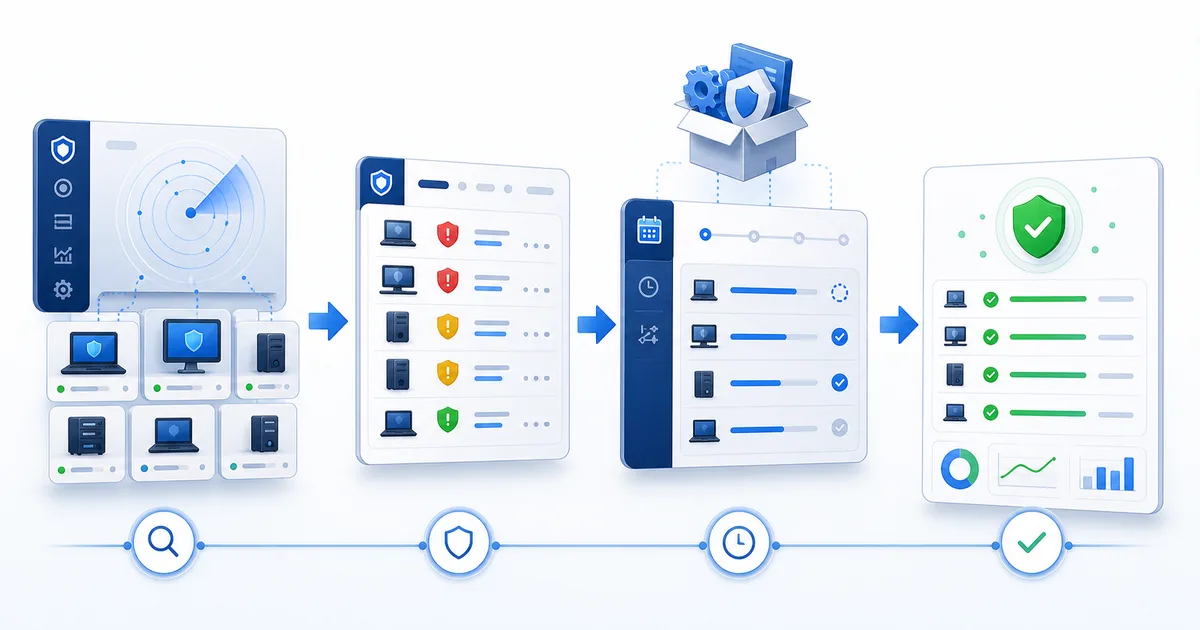
1) Detecta qué falta antes de abrir sesiones remotas
El primer error en patching es empezar por conectarte a una compu.
Si tu flujo depende de entrar equipo por equipo para saber qué falta, ya vas tarde. Antes de tocar nada necesitas una vista central: qué endpoints tienen parches pendientes, cuáles ya están al día, cuáles fallaron y cuáles no han reportado estado reciente.
Ahí cambia el trabajo. Ya no estás cazando updates a ciegas. Estás leyendo una lista operativa.
Lo importante no es solo ver "hay actualizaciones". Es poder separar:
- Equipos con parches pendientes.
- Equipos que necesitan reinicio.
- Equipos que no reportaron estado.
- Equipos donde una instalación falló.
- Clientes o grupos con más exposición acumulada.
2) Prioriza por riesgo, no por orden alfabético
Cuando todo parece urgente, nada lo es.
Un parche menor en una compu de laboratorio no tiene el mismo peso que una actualización crítica en un equipo expuesto, un servidor administrativo o una laptop usada para conectarse a clientes.
La priorización debería cruzar tres cosas:
- Criticidad del parche: si corrige una vulnerabilidad relevante o explotada.
- Exposición del endpoint: si el equipo está en uso diario, tiene acceso sensible o está más expuesto.
- Impacto operativo: si el reinicio o la instalación puede cortar trabajo importante.
Para vulnerabilidades explotadas, una referencia útil es el catálogo Known Exploited Vulnerabilities de CISA. CISA lo mantiene como fuente para vulnerabilidades explotadas en el mundo real, así que puede servir como entrada de priorización cuando necesitas separar ruido de riesgo real.
Referencia externa para priorizar riesgo
Úsalo como una señal más dentro del flujo, no como reemplazo de tu criterio técnico. Si una vulnerabilidad aparece en KEV y tienes endpoints pendientes, esa actualización debería subir de prioridad.
- Revisa si la vulnerabilidad está en el catálogo KEV de CISA.
- Cruza esa información con tus endpoints pendientes.
- Trata los equipos expuestos como prioridad crítica cuando el impacto operativo lo justifique.
El punto es simple: no empieces por "todos los equipos en bloque" si no sabes qué riesgo estás cerrando. Empieza por lo que más duele si se queda pendiente.
3) Agrupa endpoints por ventana de mantenimiento
El parche correcto en el horario equivocado también te puede meter en problemas.
Si instalas updates mientras el usuario está cerrando nómina, atendiendo clientes o haciendo una presentación, el parche se vuelve el villano. No porque esté mal, sino porque el flujo no respetó la operación.
Agrupa por contexto:
- Equipos de oficina con horario estable.
- Laptops que aparecen y desaparecen de la red.
- Clientes con ventanas de mantenimiento específicas.
- Equipos críticos que requieren aviso antes de reiniciar.
- Grupos piloto donde validas primero antes de ampliar.
Esto baja el riesgo de interrupciones y te da un orden natural: piloto, grupos normales, equipos sensibles.
4) Ejecuta con trazabilidad, no con memoria
"Creo que ya se instaló" no sirve cuando tienes 80 endpoints.
Necesitas saber qué acción se lanzó, sobre qué equipos, cuándo empezó, qué quedó pendiente y qué falló. Sin trazabilidad, el seguimiento depende de notas sueltas, capturas o memoria. Y la memoria no escala.
El flujo ideal debería dejarte responder preguntas concretas:
- ¿Qué endpoints recibieron la acción?
- ¿Cuáles instalaron correctamente?
- ¿Cuáles quedaron esperando reinicio?
- ¿Cuáles fallaron?
- ¿Cuáles no estaban disponibles?
Esto también protege al técnico. Si el cliente pregunta qué pasó, no hay que reconstruir la historia. La evidencia ya está en el flujo.
5) Verifica antes de cerrar el ciclo
El update que "terminó" no siempre cerró el riesgo.
Puede faltar reinicio. Puede haber un parche que falló. Puede existir una actualización nueva detectada después de instalar otra. Puede ser que el endpoint no haya reportado estado actualizado.
La verificación es la parte que muchos equipos saltan porque parece aburrida. Hasta que un cliente pregunta: "¿ya quedó cubierto?".
El cierre debería confirmar:
- Estado final del endpoint.
- Parches instalados.
- Parches pendientes.
- Reinicios requeridos.
- Fallos que necesitan seguimiento.
Si no puedes comprobarlo, no está cerrado. Está asumido.
| Estado | Qué significa | Acción |
|---|---|---|
| Pendiente | Falta instalar el parche | Programar ventana o incluir en el siguiente ciclo |
| Requiere reinicio | La instalación no cerró por completo | Coordinar reinicio y volver a validar |
| Fallido | El ciclo no terminó bien | Revisar causa, conectividad o error del endpoint |
| No disponible | El equipo no reportó estado | Validar agente, conexión o disponibilidad |
| Pospuesto | Se decidió no ejecutar todavía | Registrar motivo y fecha de seguimiento |
Pendiente
Falta instalar el parche
Programar ventana o incluir en el siguiente ciclo
Requiere reinicio
La instalación no cerró por completo
Coordinar reinicio y volver a validar
Fallido
El ciclo no terminó bien
Revisar causa, conectividad o error del endpoint
No disponible
El equipo no reportó estado
Validar agente, conexión o disponibilidad
Pospuesto
Se decidió no ejecutar todavía
Registrar motivo y fecha de seguimiento
6) Documenta lo justo para que el siguiente ciclo sea mejor
No necesitas escribir una novela.
Pero sí conviene dejar evidencia útil: qué grupos se atendieron, qué porcentaje quedó correcto, qué falló, qué se pospuso y qué requiere intervención manual.
Esto ayuda en tres frentes:
- Operación: sabes qué revisar mañana.
- Seguridad: puedes demostrar avance frente a riesgo.
- Cliente: puedes explicar qué se hizo sin sonar improvisado.
La documentación buena no es la más larga. Es la que permite tomar la siguiente decisión sin volver a investigar desde cero.
Cómo aterrizar este flujo en Lunixar RMM
En Lunixar RMM, el módulo de Patch Management para Windows está en beta y apunta justo a este flujo: visibilidad de parches, instalación selectiva, políticas básicas y seguimiento desde la misma consola donde administras tus endpoints.
El objetivo no es sumar otra pantalla. Es conectar patching con operación diaria: ver qué falta, actuar por grupos y regresar a verificar sin brincar entre herramientas.
Para un MSP o un equipo de TI interno, eso cambia la conversación. Ya no se trata de "a ver cuándo parcheamos". Se trata de operar con una rutina clara:
- Detectar exposición.
- Priorizar por riesgo.
- Ejecutar en ventanas controladas.
- Verificar resultados.
- Dar seguimiento a excepciones.
Lunixar RMM te ayuda a convertir ese ciclo en una práctica repetible. Si quieres probarlo en tu propia flota, la prueba gratuita dura 2 semanas, no requiere tarjeta de crédito y permite validar hasta 5 dispositivos.
Lecturas relacionadas para seguir
Si quieres conectar este flujo con decisiones prácticas, sigue con estas guías:


