
Existem patches que são instalados.
E existem patches que ficam verificados.
A diferença aparece quando algo falha, quando um cliente pede evidência, ou quando surge uma vulnerabilidade ativa e você precisa saber quais endpoints ainda estão expostos.
Aplicar patches bem não é clicar em "atualizar". É ter um fluxo completo: detectar, priorizar, executar e verificar.
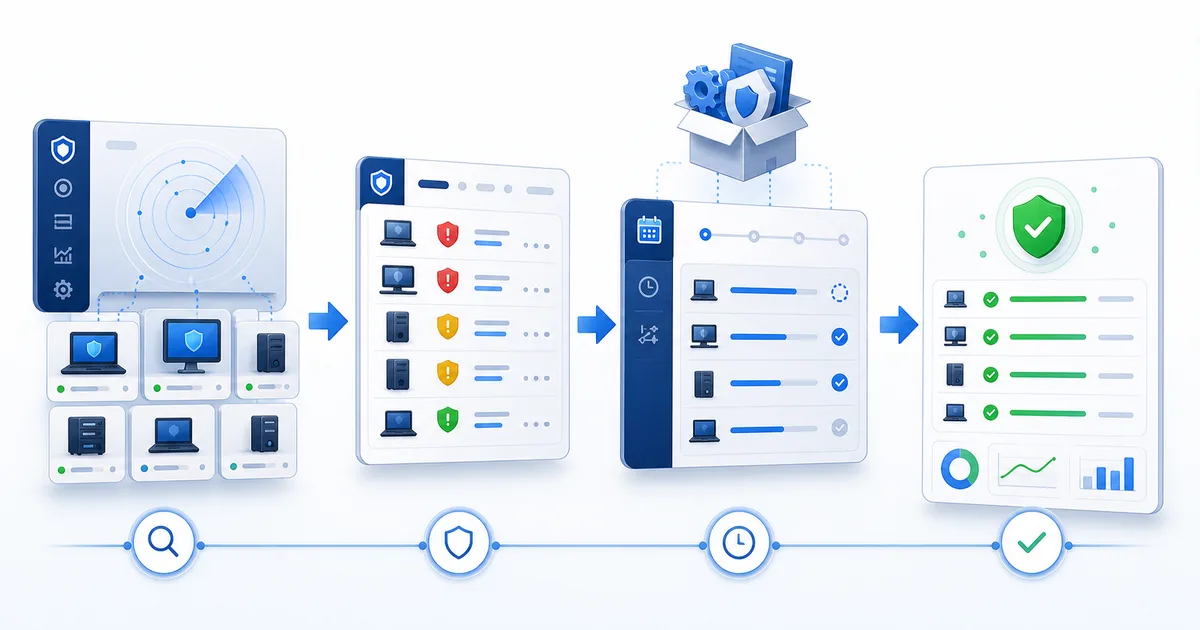
1) Detecte o que falta antes de abrir sessões remotas
O primeiro erro no patching é começar conectando em uma máquina.
Se o seu fluxo depende de entrar equipamento por equipamento para saber o que falta, você já está atrasado. Antes de tocar em qualquer coisa, precisa de uma visão central: quais endpoints têm patches pendentes, quais estão em dia, quais falharam e quais não reportaram estado recente.
É aí que o trabalho muda. Você não está caçando updates às cegas. Está lendo uma lista operacional.
O importante não é só ver "há atualizações". É conseguir separar:
- Endpoints com patches pendentes.
- Endpoints aguardando reinicialização.
- Endpoints que não reportaram estado.
- Endpoints onde a instalação falhou.
- Clientes ou grupos com mais exposição acumulada.
2) Priorize por risco, não por ordem alfabética
Quando tudo parece urgente, nada é.
Um patch menor em uma máquina de laboratório não tem o mesmo peso que uma atualização crítica em um endpoint exposto, uma estação administrativa ou um notebook usado para atender clientes.
A priorização deve cruzar três coisas:
- Criticidade do patch: se corrige uma vulnerabilidade relevante ou explorada.
- Exposição do endpoint: se a máquina é usada diariamente, tem acesso sensível ou está mais exposta.
- Impacto operacional: se a instalação ou reinicialização pode interromper trabalho importante.
Para vulnerabilidades exploradas, o catálogo Known Exploited Vulnerabilities da CISA é uma referência útil. A CISA o mantém como fonte para vulnerabilidades exploradas no mundo real, então ele pode ser uma entrada de priorização quando você precisa separar ruído de risco real.
Referência externa para priorizar risco
Use como mais um sinal dentro do fluxo, não como substituto do seu critério técnico. Se uma vulnerabilidade aparece no KEV e você tem endpoints pendentes, essa atualização deve subir na fila.
- Verifique se a vulnerabilidade aparece no catálogo KEV da CISA.
- Cruze esse sinal com endpoints que ainda precisam de atualização.
- Trate máquinas expostas como prioridade crítica quando o impacto operacional justificar.
O ponto é simples: não comece por "todos os equipamentos em bloco" se você não sabe qual risco está fechando. Comece pelo que mais pesa se ficar pendente.
3) Agrupe endpoints por janela de manutenção
O patch certo no horário errado também pode causar problema.
Se você instala updates enquanto o usuário está fechando folha, atendendo clientes ou fazendo uma apresentação, o patch vira o vilão. Não porque esteja errado, mas porque o fluxo ignorou a operação.
Agrupe por contexto:
- Máquinas de escritório com horário estável.
- Notebooks que aparecem e desaparecem da rede.
- Clientes com janelas de manutenção específicas.
- Equipamentos críticos que exigem aviso antes de reiniciar.
- Grupos piloto onde você valida antes de ampliar.
Isso reduz o risco de interrupções e dá uma ordem natural: piloto, grupos normais, endpoints sensíveis.
4) Execute com rastreabilidade, não com memória
"Acho que instalou" não funciona com 80 endpoints.
Você precisa saber qual ação foi enviada, para quais máquinas, quando começou, o que ficou pendente e o que falhou. Sem rastreabilidade, o acompanhamento depende de notas soltas, prints ou memória. E memória não escala.
O fluxo ideal deve responder perguntas concretas:
- Quais endpoints receberam a ação?
- Quais instalaram corretamente?
- Quais ficaram aguardando reinicialização?
- Quais falharam?
- Quais não estavam disponíveis?
Isso também protege o técnico. Se o cliente pergunta o que aconteceu, ninguém precisa reconstruir a história. A evidência já está no fluxo.
5) Verifique antes de fechar o ciclo
O update que "terminou" nem sempre fechou o risco.
Pode faltar reinicialização. Um patch pode ter falhado. Uma nova atualização pode aparecer depois que outra foi instalada. O endpoint pode ainda não ter reportado estado atualizado.
A verificação é a parte que muitas equipes pulam porque parece chata. Até o cliente perguntar: "já está coberto?".
O fechamento deve confirmar:
- Estado final do endpoint.
- Patches instalados.
- Patches pendentes.
- Reinicializações necessárias.
- Falhas que precisam de acompanhamento.
Se você não consegue comprovar, não está fechado. Está presumido.
| Estado | O que significa | Ação |
|---|---|---|
| Pendente | O patch ainda precisa ser instalado | Programar janela ou incluir no próximo ciclo |
| Requer reinicialização | A instalação não fechou por completo | Coordenar reinicialização e validar de novo |
| Falhou | O ciclo não terminou corretamente | Revisar causa, conectividade ou erro do endpoint |
| Indisponível | O endpoint não reportou estado | Validar agente, conexão ou disponibilidade |
| Adiado | A equipe decidiu não executar ainda | Registrar motivo e data de acompanhamento |
Pendente
O patch ainda precisa ser instalado
Programar janela ou incluir no próximo ciclo
Requer reinicialização
A instalação não fechou por completo
Coordenar reinicialização e validar de novo
Falhou
O ciclo não terminou corretamente
Revisar causa, conectividade ou erro do endpoint
Indisponível
O endpoint não reportou estado
Validar agente, conexão ou disponibilidade
Adiado
A equipe decidiu não executar ainda
Registrar motivo e data de acompanhamento
6) Documente o suficiente para melhorar o próximo ciclo
Você não precisa escrever um romance.
Mas vale deixar evidência útil: quais grupos foram atendidos, qual percentual ficou correto, o que falhou, o que foi adiado e o que exige intervenção manual.
Isso ajuda em três frentes:
- Operação: você sabe o que revisar amanhã.
- Segurança: consegue demonstrar avanço contra risco.
- Cliente: consegue explicar o que foi feito sem parecer improvisado.
Boa documentação não é a mais longa. É a que permite tomar a próxima decisão sem investigar tudo de novo.
Como levar esse fluxo para o Lunixar RMM
No Lunixar RMM, o módulo de Patch Management para Windows está em beta e mira exatamente esse tipo de fluxo: visibilidade de patches, instalação seletiva, políticas básicas e acompanhamento no mesmo console onde você administra seus endpoints.
O objetivo não é somar outra tela. É conectar patching com a operação diária: ver o que falta, agir por grupos e voltar para verificar sem pular entre ferramentas.
Para um MSP ou equipe interna de TI, isso muda a conversa. Não é "vamos aplicar patches quando der". É uma rotina clara:
- Detectar exposição.
- Priorizar por risco.
- Executar em janelas controladas.
- Verificar resultados.
- Acompanhar exceções.
Lunixar RMM ajuda a transformar esse ciclo em uma prática repetível. Se quiser testar na sua própria frota, o teste grátis dura 2 semanas, não exige cartão de crédito e permite validar até 5 dispositivos.
Leituras relacionadas
Se quiser conectar esse fluxo com decisões práticas, continue com estes guias:


