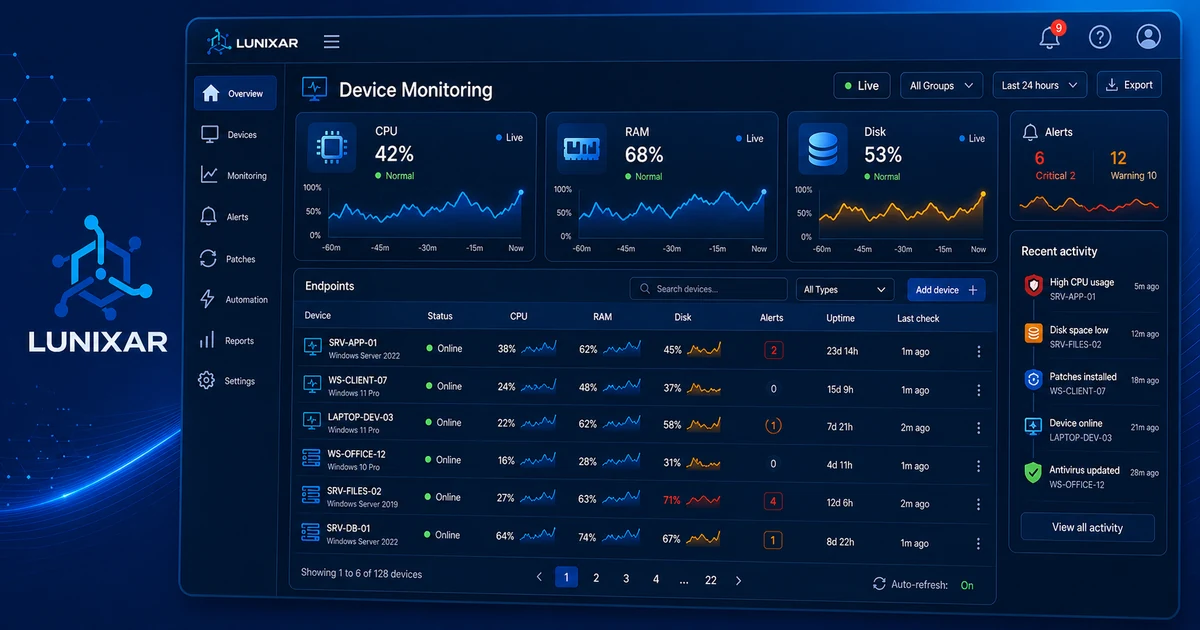
Alguns alertas salvam o dia.
Outros só criam ruído.
A diferença está na política.
Se você está começando com RMM, não ligue todas as notificações no primeiro dia. Comece com uma política operacional pequena: quais sinais importam, quem responde, quando escalam e que evidência deve ficar registrada.

1) Comece com poucos alertas, mas que realmente doem
A tentação é óbvia: "vamos alertar tudo".
CPU, RAM, disco, antivírus, usuários, sessões, patches, serviços, qualquer mudança. Parece completo... até chegarem 80 e-mails e ninguém ler o número 81.
Para uma primeira política, escolha sinais com ação clara:
LowDiskSpace: ainda dá tempo de liberar espaço antes que o computador fique inútil.DiskSmartPredictedFailure: você tem uma janela para fazer backup ou trocar o disco.AntivirusDisabled: um endpoint Windows perdeu uma proteção básica.MalwareDetected: o Defender encontrou algo e você precisa de contexto.FailedLoginBurstouAccountLockoutBurst: pode ser erro do usuário, mas também pode ser força bruta ou credencial mal usada.
Você não está buscando perfeição. Está buscando sinais que façam alguém agir.
2) Separe segurança, continuidade e manutenção
Nem todo alerta entra no mesmo carril.
Um alerta de malware não se trata como pouco espaço em disco. Uma rajada de logins falhos não tem a mesma urgência que um endpoint offline que você já sabia que estava desligado.
Divida sua primeira política em três grupos:
| Grupo | Exemplos | Resposta esperada |
|---|---|---|
| Segurança | MalwareDetected, AntivirusDisabled, SecurityLogCleared, PrivilegedGroupMembershipChange | Revisar contexto, executar ação de segurança e documentar |
| Continuidade | DiskSmartPredictedFailure, endpoint crítico offline, disco cheio | Evitar queda, fazer backup, liberar espaço ou trocar hardware |
| Manutenção | patches pendentes, inventário desatualizado, mudanças esperadas | Agendar acompanhamento sem interromper o urgente |
Segurança
MalwareDetected, AntivirusDisabled, SecurityLogCleared, PrivilegedGroupMembershipChange
Revisar contexto, executar ação de segurança e documentar
Continuidade
DiskSmartPredictedFailure, endpoint crítico offline, disco cheio
Evitar queda, fazer backup, liberar espaço ou trocar hardware
Manutenção
patches pendentes, inventário desatualizado, mudanças esperadas
Agendar acompanhamento sem interromper o urgente
Isso ajuda o técnico a não pular de um alerta menor para um sinal crítico como se fossem iguais.
3) Defina quando escalar antes do incêndio
Um alerta isolado pode esperar.
Um padrão não.
Exemplo: um login falho em um notebook pode ser só senha digitada errado. Uma rajada de falhas em uma conta privilegiada, seguida de bloqueio, já merece outra leitura. O mesmo vale para disco: 18% livre talvez não seja urgente, mas 6% em um servidor de faturamento numa segunda às 9h vai te cobrar.
Sua política deve dizer:
- quais alertas o técnico de primeira linha atende;
- quais alertas escalam para o responsável pelo cliente;
- quais alertas exigem ação imediata;
- quando criar ticket;
- quando avisar o cliente;
- o que documentar ao fechar.
Como referências externas, os CISA Cybersecurity Performance Goals reforçam capacidade de detecção, monitoramento e reporte para ameaças relevantes. O NIST SP 800-61 Rev. 3 também trata resposta a incidentes como um ciclo preparado, não improvisado.
4) Conecte alerta com contexto, não só e-mail
O e-mail avisa.
Mas não resolve.
Quando um alerta chega, o técnico precisa de contexto rápido:
- qual endpoint é;
- quem usa;
- quais alertas recentes existem;
- qual software e inventário ele tem;
- quais patches estão pendentes;
- se isso já aconteceu antes;
- qual ação foi feita da última vez.
Esse contexto funciona melhor perto de monitoramento de dispositivos, alertas, inventário e gerenciamento de patches. Se cada dado vive em uma ferramenta diferente, o técnico perde minutos reconstruindo a história.
5) No Windows, decida qual ação vem depois
Uma boa política não termina em "recebemos um alerta".
Ela termina em ação.
Em endpoints Windows com Defender, o Lunixar RMM ajuda a passar de sinal para resposta com ações como UpdateSignatures, QuickScan, FullScan e RemoveThreats quando aplicável. A Microsoft documenta que quick scans do Defender costumam ser a opção recomendada para scans programados ou sob demanda na maioria dos casos, junto com proteção em tempo real.
Isso não significa que todo alerta precise de full scan. Significa que sua política deve decidir por gravidade:
AntivirusDisabled: revisar status e restaurar proteção.MalwareDetected: atualizar assinaturas, revisar detalhe e executar scan conforme gravidade.DefenderExclusionAdded: validar se a exclusão foi autorizada.SecurityLogCleared: tratar como sinal sensível e revisar quem fez a mudança.
Para Linux, mantenha a expectativa correta dentro deste fluxo: inventário e visibilidade de segurança, não ações remotas de Defender. O gerenciamento de patches de Linux vive no módulo de patches, não nas ações de segurança do Defender.
6) Use uma política mínima que qualquer pessoa consiga seguir
A política não ajuda se ela só vive na cabeça do técnico senior.
Ela precisa ser visível, curta e repetível.
Uma primeira versão pode ser assim:
| Alerta | Severidade inicial | Responsável | Tempo de resposta | Ação esperada | Evidência de fechamento |
|---|---|---|---|---|---|
MalwareDetected | Crítica | Segurança / técnico senior | Hoje | Atualizar assinaturas, revisar detalhes e executar scan conforme gravidade | Resultado do scan e ação tomada |
AntivirusDisabled | Alta | Técnico designado | Hoje | Validar status e restaurar proteção | Estado final do antivírus |
DiskSmartPredictedFailure | Alta | Técnico designado | 24 horas | Fazer backup, revisar troca e avisar o cliente | Plano de troca ou mitigação |
LowDiskSpace | Média | Primeira linha | 48 horas | Liberar espaço ou agendar limpeza | Espaço recuperado e causa provável |
FailedLoginBurst | Alta se afeta conta crítica | Segurança / responsável pelo cliente | Hoje | Revisar conta, origem e padrão | Conta revisada e próximo passo |
MalwareDetected
Crítica
Segurança / técnico senior
Hoje
Atualizar assinaturas, revisar detalhes e executar scan conforme gravidade
Resultado do scan e ação tomada
AntivirusDisabled
Alta
Técnico designado
Hoje
Validar status e restaurar proteção
Estado final do antivírus
DiskSmartPredictedFailure
Alta
Técnico designado
24 horas
Fazer backup, revisar troca e avisar o cliente
Plano de troca ou mitigação
LowDiskSpace
Média
Primeira linha
48 horas
Liberar espaço ou agendar limpeza
Espaço recuperado e causa provável
FailedLoginBurst
Alta se afeta conta crítica
Segurança / responsável pelo cliente
Hoje
Revisar conta, origem e padrão
Conta revisada e próximo passo
Não precisa ser perfeita. Precisa evitar improviso.
Template rápido para sua política de alertas RMM
Copie esta estrutura e adapte por cliente:
``text Se [alerta] aparecer em [tipo de endpoint], revisar [contexto mínimo], executar [ação esperada], criar ticket se [condição], escalar para [responsável] se [condição], fechar somente depois de documentar [resultado]. ``
Exemplo:
``text Se AntivirusDisabled aparecer em um servidor Windows, revisar status do Defender e alertas recentes, restaurar proteção e executar UpdateSignatures, criar ticket se a proteção não voltar ao estado normal, escalar para o responsável pelo cliente se coincidir com MalwareDetected, fechar somente depois de documentar o estado final do antivírus. ``
FAQ: primeira política de alertas RMM
Quais alertas devo ativar primeiro em um RMM?
Comece por alertas com ação clara: LowDiskSpace, DiskSmartPredictedFailure, AntivirusDisabled, MalwareDetected, FailedLoginBurst e AccountLockoutBurst. Depois adicione sinais conforme o tipo de cliente e a criticidade dos endpoints.
Como evitar alertas demais?
Não ative alertas sem responsável, severidade e ação esperada. Se um alerta não muda uma decisão, provavelmente só adiciona ruído. Revise semanalmente quais alertas foram úteis e quais ninguém atendeu.
Todo alerta deve criar um ticket?
Não. Alguns alertas só precisam de revisão ou fechamento rápido. Crie ticket quando o caso exige acompanhamento, autorização, comunicação com o cliente, evidência ou várias ações. Se tudo vira ticket, o quadro vira outra caixa de entrada.
Quais alertas são críticas para MSPs?
As críticas geralmente afetam segurança ou continuidade: malware, antivírus desativado, logs de segurança apagados, mudanças em grupos privilegiados, falha prevista de disco e rajadas de login em contas sensíveis.
Todo cliente precisa da mesma política?
Não. Você pode começar com uma base comum, mas servidores, estações administrativas, pontos de venda e laptops de usuários não têm o mesmo impacto. Ajuste a política por criticidade.
Feche o ciclo: menos alertas, melhores decisões
A primeira política de alertas RMM não precisa ser enorme.
Precisa ser útil.
Comece com sinais de segurança, continuidade e manutenção. Conecte cada alerta com contexto. Defina quem responde. Documente fechamento. Ajuste toda semana.
Lunixar RMM encaixa nesse fluxo porque conecta monitoramento, alertas, inventário, patches, segurança e acesso remoto em uma só operação. Se hoje seus alertas vivem como e-mails soltos, o teste de 2 semanas permite validar o fluxo com até 5 dispositivos, sem cartão e com acesso completo.
Você também pode seguir com estes guias: