Tem segundas que comecam sozinhas.
Tres mensagens antes do cafe.
Um cliente dizendo "esta tudo lento".
E um console cheio de alertas que ninguem revisou na sexta.
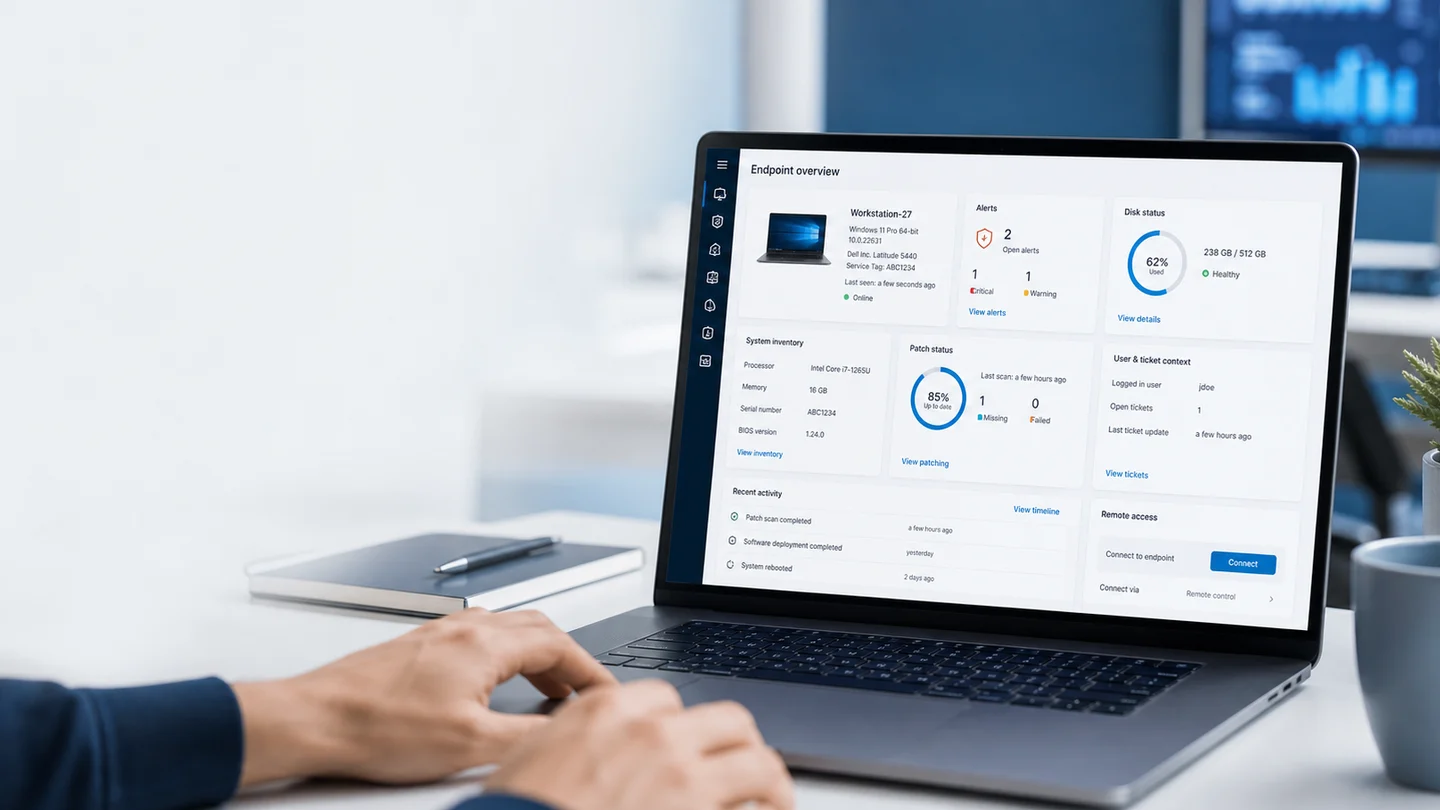
A diferenca entre comecar a semana com controle e comecar no caos nao e sorte. E uma rotina curta. Uma revisao semanal que mostra o que esta saudavel, o que esta estranho e o que precisa de acao antes de virar ticket.
Este guia e para MSPs pequenos e equipes internas de TI. Nao e ritual burocratico. E uma forma pratica de usar o RMM como painel operacional da segunda-feira.
Como base externa, vale acompanhar tres referencias oficiais: o guia do NIST sobre planejamento de gerenciamento de patches empresarial, os Cybersecurity Performance Goals da CISA e o catalogo Known Exploited Vulnerabilities da CISA. Na operacao diaria, isso vira inventario claro, patches priorizados, evidencia de exploracao e acompanhamento constante.
1) Dispositivos offline: quem sumiu do mapa
Comece pelo simples: quais dispositivos pararam de reportar.
Um endpoint offline pode ser normal. Um notebook desligado, um PC fora do horario, um dispositivo que alguem deixou em casa.
Mas tambem pode ser:
- um agente quebrado,
- uma maquina sem rede,
- um endpoint removido sem aviso,
- um servidor que parou de responder,
- ou um cliente inteiro com problema de conectividade.
A ideia nao e entrar em panico. A ideia e separar silencio esperado de silencio estranho.
Para um MSP, isso tambem mostra clientes com baixa disciplina operacional: maquinas que aparecem e somem, agentes que nao voltam, dispositivos que ninguem sabe de quem sao.
2) Alertas abertos: ruido antigo vai te cobrar
Os alertas de segunda nao sao todos iguais.
Existem alertas novos, alertas repetidos e alertas antigos que alguem deixou "para depois".
Organize assim:
- novos desde sexta-feira: algo pode ter acontecido fora do horario;
- repetidos no mesmo endpoint: normalmente apontam para causa raiz nao resolvida;
- abertos ha mais de uma semana: agora sao divida operacional;
- seguranca ou autenticacao: nao misture com ruido normal.
No Lunixar RMM, alertas como LowDiskSpace, DiskSmartPredictedFailure, AntivirusDisabled, MalwareDetected, FailedLoginBurst, AccountLockoutBurst, SecurityLogCleared ou PrivilegedGroupMembershipChange nao deveriam ficar no mesmo balde. Alguns sao manutencao. Outros sao investigacao.
3) Disco e saude do hardware: antes que o usuario perca trabalho
Disco baixo nao parece urgente.
Ate nao sobrar espaco para atualizacoes, logs, temporarios ou trabalho real.
Risco SMART nao parece urgente.
Ate o disco falhar e agora voce esta restaurando, nao prevenindo.
Na segunda, revise:
- dispositivos com pouco espaco livre;
- endpoints com crescimento rapido de disco;
- alertas de saude de disco;
- servidores ou PCs de usuarios-chave perto do limite;
- padroes repetidos por cliente ou departamento.
O inventario ajuda muito aqui. Se um dispositivo mudou software, comecou a gerar logs ou recebeu arquivos grandes, voce entende a historia antes de abrir acesso remoto.
4) Patches: o que falta, o que pesa e o que vem primeiro
O NIST trata gerenciamento de patches como manutencao preventiva, nao como reacao de ultima hora. Isso importa: patches nao sao uma tarefa isolada. Sao parte de manter a operacao saudavel.
Na segunda, revise:
- dispositivos com patches pendentes;
- endpoints onde atualizacoes falharam;
- sistemas ha mais tempo sem manutencao;
- clientes ou areas com maior exposicao;
- vulnerabilidades com evidencia de exploracao publica.
E aqui que a CISA KEV ajuda. Se uma vulnerabilidade esta no catalogo Known Exploited Vulnerabilities, nao e apenas "alta severidade". Existe evidencia de exploracao no mundo real. Essa lista ajuda a decidir o que vem primeiro quando tudo parece urgente.
5) Seguranca: sinais que nao devem se misturar com manutencao
Segunda tambem e um bom momento para revisar mudancas de seguranca que aconteceram enquanto ninguem olhava de perto.
Preste atencao em:
- antivirus desativado;
- malware detectado;
- novas exclusoes no Defender;
- muitas tentativas de login falhas;
- bloqueios de conta em volume;
- grupos privilegiados alterados;
- logs de seguranca apagados;
- politica de auditoria alterada.
Nem todo sinal significa incidente. Mas todo sinal merece contexto.
Se voce ve AntivirusDisabled, verifique se houve software novo instalado. Se ve FailedLoginBurst, confira origem e conta. Se ve SecurityLogCleared, nao feche como manutencao sem investigar.
6) Inventario: o que mudou sem ninguem avisar
Inventario nao e so uma lista bonita.
E a memoria operacional da sua frota.
Na segunda, revise:
- software novo instalado;
- software removido;
- mudancas de hardware;
- novos dispositivos;
- dispositivos que nao deveriam mais estar ativos;
- diferencas estranhas entre snapshots.
Isso ajuda muito MSPs porque clientes mudam coisas sem avisar. Tambem ajuda TI interno porque usuarios instalam software, conectam hardware ou movem maquinas sem abrir ticket.
7) Acoes de acompanhamento: o que acontece hoje, o que agenda, o que fecha
Uma revisao semanal nao serve se termina em "temos que ver isso".
Termine com tres listas:
- acao hoje: seguranca, disco critico, servidores, patches de alto risco;
- acao agendada: manutencao, atualizacoes, limpeza, acompanhamento com usuario;
- fechar ou documentar: alertas resolvidos, dispositivos removidos, falsos positivos confirmados.
Para um MSP, essa lista tambem prova valor para o cliente: "encontramos isso, corrigimos isso, isso continua pendente". Para TI interno, ajuda a justificar trabalho preventivo que normalmente ninguem ve.
Fechamento
Uma boa segunda-feira em TI nao significa zero problemas.
Significa saber quais importam primeiro.
Uma rotina semanal de RMM ajuda voce a sair da reacao e ir para priorizacao: dispositivos offline, alertas, disco, patches, seguranca, inventario e acompanhamento. Voce nao precisa revisar tudo com a mesma profundidade. Precisa de uma ordem.
Lunixar RMM encaixa nesse fluxo porque conecta monitoramento, inventario, alertas, seguranca e acoes operacionais em um unico console. Se hoje sua segunda depende de chats, planilhas e memoria, um teste de 2 semanas pode ajudar a transformar isso em processo.
Leituras relacionadas para continuar
Se voce quer transformar essa rotina em uma operacao mais forte, continue com estes guias: