
La gestión de parches Linux no falla porque falten comandos.
Falla porque falta un proceso.
Un equipo puede saber usar apt, dnf, yum o zypper, y aun así perder visibilidad cuando administra muchos servidores, estaciones técnicas, VMs, contenedores base o ambientes de clientes. El problema real no es instalar paquetes. Es saber qué está pendiente, qué riesgo importa, qué se probó, qué se aplicó y qué sigue expuesto.
Este checklist está pensado para MSPs y departamentos de TI que quieren convertir los parches Linux en una operación repetible, auditable y menos dependiente de memoria.
Para entender el flujo completo antes de ejecutar el checklist, consulta la guía operativa de gestión de parches Linux con RMM.
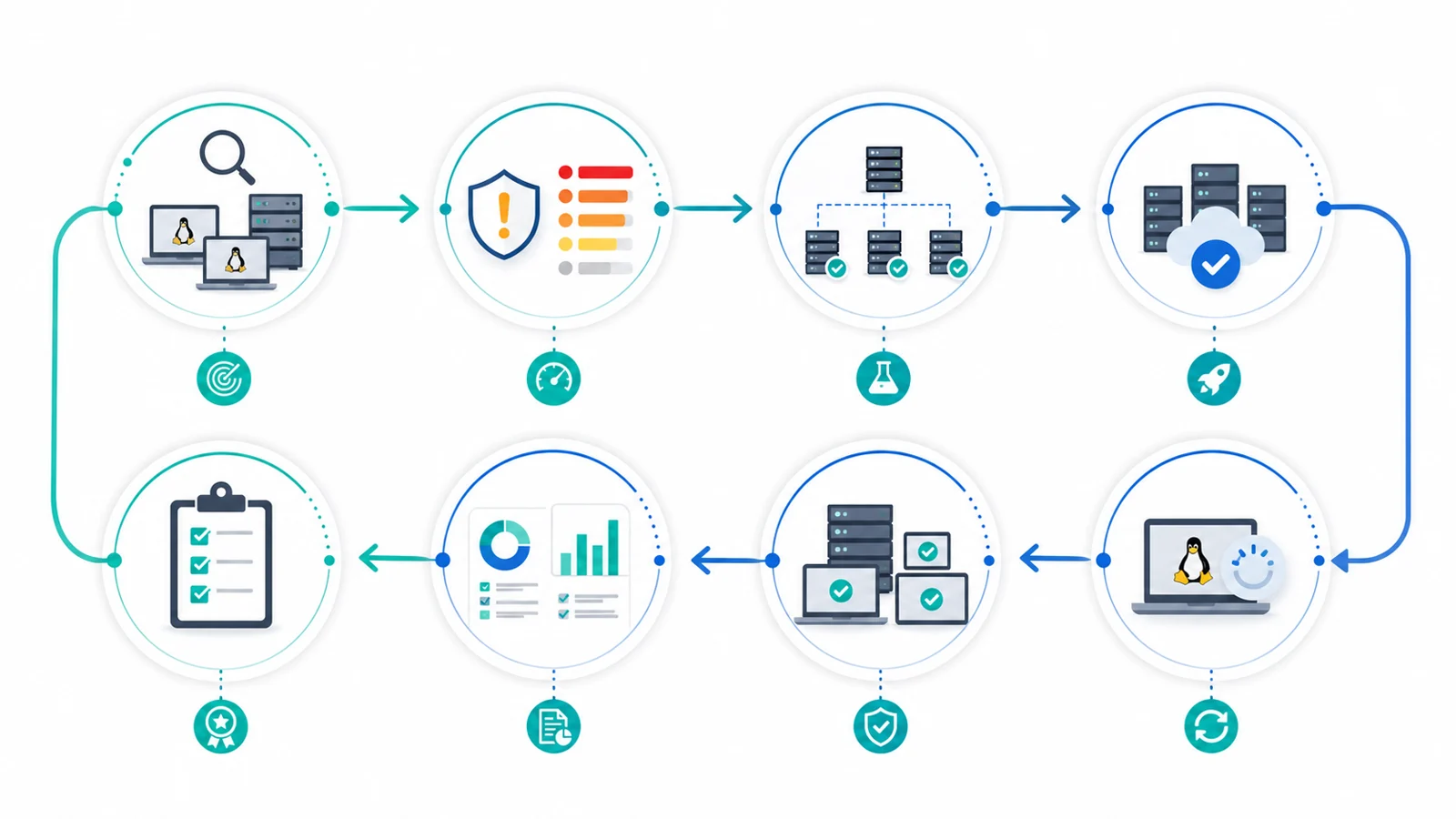
Checklist rápido
Antes de ejecutar una ventana de actualización, confirma que puedes responder estas preguntas:
- ¿Qué equipos Linux existen y qué distribución ejecutan?
- ¿Qué versión de sistema, kernel y paquetes críticos reportan?
- ¿Qué activos son productivos, expuestos a internet o críticos para el negocio?
- ¿Qué CVE, avisos del fabricante o vulnerabilidades explotadas afectan a esos paquetes?
- ¿Qué equipos entran primero a pruebas y cuáles esperan a producción?
- ¿Qué servicios pueden reiniciarse y cuáles requieren coordinación?
- ¿Qué evidencia quedará después: pendiente, instalado, fallido, reinicio requerido o verificado?
Si una de esas respuestas vive solo en una terminal, un chat o una hoja de cálculo manual, la operación todavía es frágil.
1) Inventario: empieza por lo que realmente existe
El primer paso de la gestión de parches Linux es inventario.
No basta con saber que “hay servidores Linux”. Necesitas distinguir distribución, versión, kernel activo, repositorios configurados, rol del equipo, criticidad, dueño técnico y estado de conexión.
Una flota mixta puede incluir Ubuntu, Debian, Rocky Linux, AlmaLinux, Red Hat Enterprise Linux, estaciones de soporte, máquinas de laboratorio y servidores productivos. Tratar todo igual crea ruido. Ignorar esa diversidad crea riesgo.
En Lunixar, esta parte se conecta con gestión de dispositivos, inventario y gestión de parches. El objetivo es que el mantenimiento parta de endpoints conocidos, no de listas incompletas.
2) Prioriza por riesgo, no por volumen
Una lista con cientos de paquetes pendientes no dice por sí sola qué arreglar primero.
Para priorizar, combina varias señales:
- criticidad del activo;
- exposición del servicio;
- severidad del CVE;
- evidencia de explotación real;
- probabilidad de explotación;
- impacto operativo si el parche falla;
- disponibilidad de una ventana de mantenimiento.
El catálogo CISA Known Exploited Vulnerabilities ayuda a identificar vulnerabilidades con explotación conocida. La National Vulnerability Database de NIST permite consultar CVE y datos de vulnerabilidad. FIRST EPSS puede apoyar la priorización con una estimación probabilística de explotación.
La decisión práctica es simple: no todos los parches pendientes merecen la misma urgencia.
3) Separa seguridad, kernel, runtimes y servicios
En Linux, un update puede ser trivial o puede cambiar una pieza sensible.
No es lo mismo actualizar documentación o utilidades menores que tocar kernel, OpenSSL, glibc, OpenSSH, runtimes de aplicaciones, drivers, agentes, bases de datos o servicios expuestos.
Clasificar los cambios ayuda a decidir:
- qué puede instalarse en una ventana normal;
- qué requiere pruebas previas;
- qué necesita reinicio;
- qué debe coordinarse con una aplicación;
- qué no conviene mezclar con otros cambios.
Los avisos de seguridad de distribución también importan. Para Linux, revisa fuentes como Ubuntu Security Notices, Red Hat Security Data y el Debian Security Tracker.
4) Prueba por anillos antes de producción
Un buen flujo no empieza con todos los servidores productivos.
Empieza con grupos pequeños.
Puedes organizar anillos como:
- laboratorio o ambiente de prueba;
- endpoints internos de bajo impacto;
- servidores no críticos;
- clientes o áreas piloto;
- producción crítica.
El propósito no es retrasar seguridad. Es reducir el riesgo de romper servicios por dependencias, repositorios, reinicios pendientes o cambios de comportamiento.
Este enfoque encaja especialmente bien cuando administras una flota mixta Windows y Linux. Cada sistema operativo tiene sus reglas, pero el control operativo debe verse desde una sola agenda de mantenimiento.
5) Define ventanas y criterios de salida
Una ventana de parches no debería decir solo “actualizar servidores”.
Debería incluir:
- alcance de equipos;
- paquetes o familias de paquetes esperadas;
- horario de inicio y cierre;
- responsables;
- servicios que se deben validar;
- política de reinicio;
- criterio para detener la ejecución;
- criterio para declarar el trabajo terminado.
El punto más importante es el criterio de salida. “El comando terminó” no significa “la vulnerabilidad quedó cerrada”.
Una salida útil distingue pendiente, instalado, fallido, retenido, reinicio requerido y verificado. Ese detalle permite explicar el estado real al cliente, al área de seguridad o a dirección.
6) Verifica después del update
La verificación posterior es donde muchos procesos se quedan cortos.
Después de instalar parches, revisa al menos:
- si el kernel activo cambió o requiere reinicio;
- si hay servicios caídos;
- si quedaron paquetes retenidos;
- si el repositorio respondió correctamente;
- si el paquete vulnerable realmente cambió de versión;
- si el endpoint volvió a reportar estado;
- si hay alertas nuevas después del mantenimiento.
Para una operación más completa, conecta este paso con el flujo de detección y verificación de parches. La métrica que importa no es solo “ejecuciones iniciadas”, sino “equipos realmente corregidos”.
7) Reporta cumplimiento, fallos y riesgo residual
Los reportes son parte del trabajo, no una formalidad al final.
Un reporte útil de gestión de parches Linux debe mostrar:
- endpoints al día;
- endpoints pendientes;
- parches críticos aplicados;
- fallos por equipo;
- reinicios pendientes;
- vulnerabilidades que siguen abiertas;
- responsables y siguiente acción.
Para un MSP, esto ayuda a demostrar servicio. Para TI interna, ayuda a justificar ventanas, priorizar tareas y mostrar reducción de riesgo.
8) Cómo ayuda un RMM
Un RMM no debe ser solo un botón para correr updates.
Debe ayudar a centralizar el contexto:
- inventario de endpoints;
- estado de parches;
- priorización operativa;
- ejecución controlada;
- alertas y fallos;
- evidencia posterior;
- reportes por cliente o área.
Si hoy tus parches Linux dependen de sesiones SSH sueltas, scripts no trazables o notas manuales, el primer salto no es automatizar todo. Es ordenar la visibilidad.
Desde ahí puedes evaluar Lunixar RMM, la página de gestión de parches y el artículo específico sobre parches Linux desde un RMM. Si quieres probarlo con una flota real, inicia una prueba gratis.


