
O gerenciamento de patches Linux normalmente não falha porque faltam comandos.
Ele falha porque falta processo.
Um técnico pode conhecer apt, dnf, yum ou zypper e, ainda assim, perder visibilidade ao administrar muitos servidores, estações técnicas, VMs, imagens base e ambientes de clientes. O problema real não é instalar pacotes. É saber o que está pendente, que risco importa, o que foi testado, o que foi aplicado e o que continua exposto.
Este checklist foi criado para MSPs e equipes de TI que querem transformar os patches Linux em uma operação repetível, auditável e menos dependente de memória.
Para entender o fluxo completo antes de executar o checklist, consulte o guia operacional de gerenciamento de patches Linux com RMM.
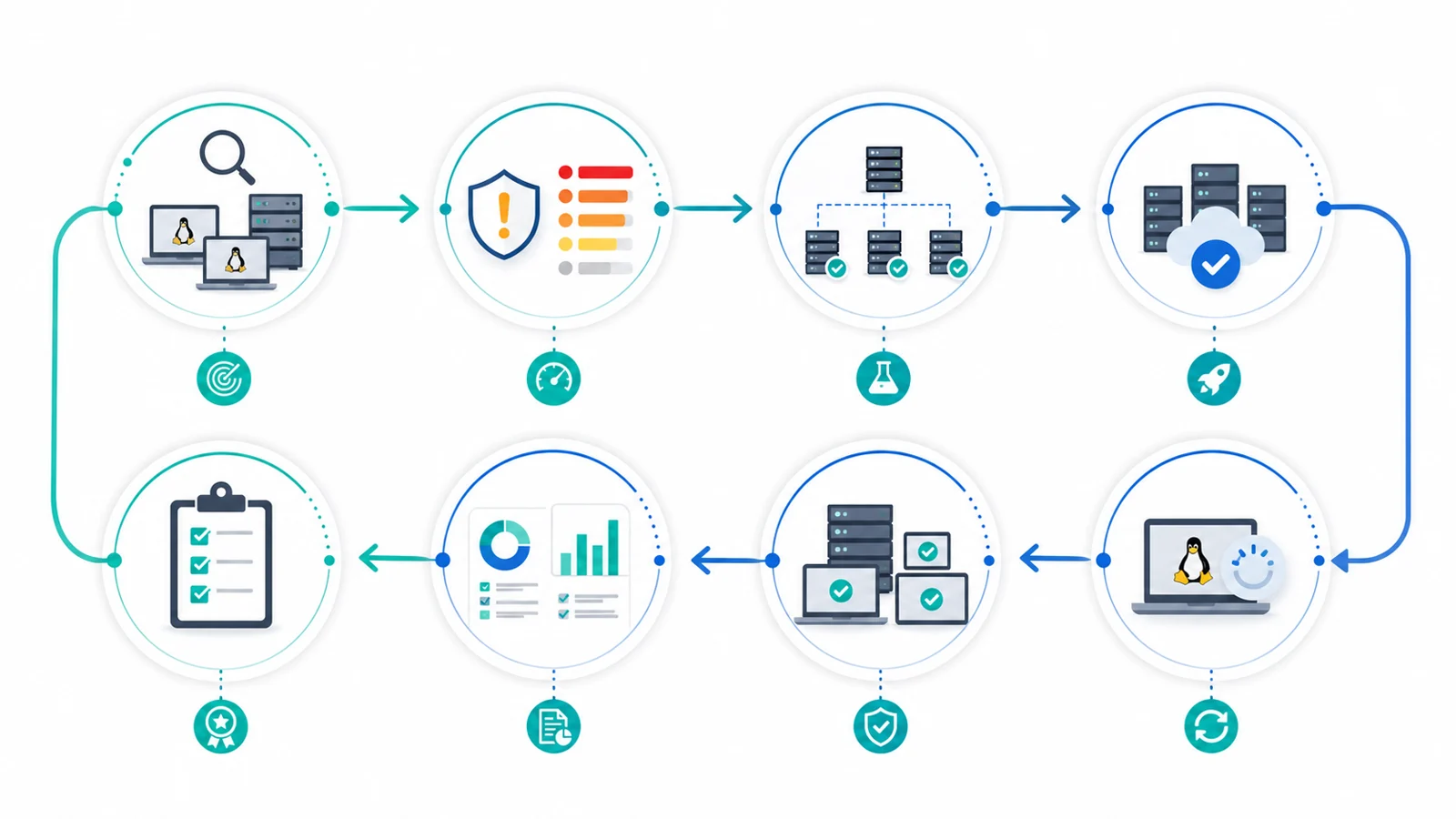
Checklist rápido
Antes de executar uma janela de atualização, confirme que você consegue responder:
- Quais endpoints Linux existem e quais distribuições eles executam?
- Qual versão do sistema, kernel ativo e pacotes críticos eles reportam?
- Quais ativos são produtivos, expostos à internet ou críticos para o negócio?
- Quais CVEs, avisos do fabricante ou vulnerabilidades exploradas afetam esses pacotes?
- Quais endpoints entram primeiro em testes e quais esperam a produção?
- Quais serviços podem reiniciar e quais exigem coordenação?
- Qual evidência ficará depois: pendente, instalado, falhou, reinicialização necessária ou verificado?
Se uma dessas respostas existe apenas em uma sessão de terminal, conversa ou planilha manual, a operação ainda é frágil.
1) Inventário: comece pelo que realmente existe
O gerenciamento de patches Linux começa com inventário.
Não basta saber que “temos servidores Linux”. Você precisa distinguir distribuição, versão, kernel ativo, repositórios configurados, função do endpoint, criticidade, responsável técnico e estado de conexão.
Uma frota mista pode incluir Ubuntu, Debian, Rocky Linux, AlmaLinux, Red Hat Enterprise Linux, estações de suporte, máquinas de laboratório e servidores produtivos. Tratar tudo igual cria ruído. Ignorar essa diversidade cria risco.
No Lunixar, essa parte se conecta com gerenciamento de dispositivos, inventário e gerenciamento de patches. A manutenção deve partir de endpoints conhecidos, não de listas incompletas.
2) Priorize por risco, não por volume
Uma lista longa de pacotes pendentes não diz, por si só, o que corrigir primeiro.
Para priorizar, combine vários sinais:
- criticidade do ativo;
- exposição do serviço;
- severidade do CVE;
- evidência de exploração real;
- probabilidade de exploração;
- impacto operacional se o patch falhar;
- disponibilidade de janela de manutenção.
O catálogo CISA Known Exploited Vulnerabilities ajuda a identificar vulnerabilidades com exploração conhecida. A National Vulnerability Database do NIST permite consultar CVEs e dados de vulnerabilidade. O FIRST EPSS pode apoiar a priorização com uma estimativa probabilística de exploração.
A decisão prática é simples: nem todo patch pendente merece a mesma urgência.
3) Separe segurança, kernel, runtimes e serviços
No Linux, uma atualização pode ser simples ou pode tocar uma peça sensível.
Atualizar documentação ou utilitários menores não é o mesmo que alterar kernel, OpenSSL, glibc, OpenSSH, runtimes de aplicações, drivers, agentes, bancos de dados ou serviços expostos.
Classificar mudanças ajuda a decidir:
- o que pode entrar em uma janela normal;
- o que exige testes prévios;
- o que precisa de reinicialização;
- o que deve ser coordenado com o dono da aplicação;
- o que não convém misturar com outras mudanças.
Avisos de segurança das distribuições também importam. Para Linux, use fontes como Ubuntu Security Notices, Red Hat Security Data e o Debian Security Tracker.
4) Teste por anéis antes da produção
Um bom fluxo não começa com todos os servidores produtivos.
Ele começa com grupos pequenos.
Você pode organizar anéis como:
- laboratório ou ambiente de teste;
- endpoints internos de baixo impacto;
- servidores não críticos;
- clientes ou áreas piloto;
- produção crítica.
O objetivo não é atrasar segurança. É reduzir o risco de quebrar serviços por dependências, repositórios, reinicializações pendentes ou mudanças de comportamento.
Esse enfoque funciona especialmente bem ao administrar uma frota mista Windows e Linux. Cada sistema operacional tem suas regras, mas o controle operacional deve aparecer em uma única agenda de manutenção.
5) Defina janelas e critérios de saída
Uma janela de patches não deveria dizer apenas “atualizar servidores”.
Ela deveria incluir:
- escopo de endpoints;
- pacotes ou famílias de pacotes esperadas;
- horário de início e fim;
- responsáveis;
- serviços que devem ser validados;
- política de reinicialização;
- critério para interromper a execução;
- critério para declarar o trabalho concluído.
O ponto mais importante é o critério de saída. “O comando terminou” não significa “a vulnerabilidade foi fechada”.
Uma saída útil distingue pendente, instalado, falhou, retido, reinicialização necessária e verificado. Esse detalhe permite explicar o estado real ao cliente, à equipe de segurança ou à diretoria.
6) Verifique depois do update
A verificação posterior é onde muitos processos ficam incompletos.
Depois de instalar patches, revise pelo menos:
- se o kernel ativo mudou ou exige reinicialização;
- se há serviços parados;
- se ficaram pacotes retidos;
- se o repositório respondeu corretamente;
- se o pacote vulnerável realmente mudou de versão;
- se o endpoint voltou a reportar estado;
- se surgiram novos alertas depois da manutenção.
Para uma operação mais completa, conecte este passo com o fluxo de detecção e verificação de patches. A métrica importante não é apenas “execuções iniciadas”, mas “endpoints realmente corrigidos”.
7) Relate conformidade, falhas e risco residual
Relatórios fazem parte do trabalho, não são uma formalidade final.
Um relatório útil de gerenciamento de patches Linux deve mostrar:
- endpoints atualizados;
- endpoints ainda pendentes;
- patches críticos aplicados;
- falhas por endpoint;
- reinicializações pendentes;
- vulnerabilidades ainda abertas;
- responsável e próxima ação.
Para um MSP, isso ajuda a demonstrar serviço. Para TI interna, ajuda a justificar janelas, priorizar tarefas e mostrar redução de risco.
8) Como um RMM ajuda
Um RMM não deve ser apenas um botão para executar updates.
Ele deve centralizar contexto:
- inventário de endpoints;
- estado de patches;
- priorização operacional;
- execução controlada;
- alertas e falhas;
- evidência posterior;
- relatórios por cliente ou área.
Se hoje seus patches Linux dependem de sessões SSH soltas, scripts sem rastreabilidade ou notas manuais, o primeiro salto não é automatizar tudo. É organizar a visibilidade.
A partir daí, avalie Lunixar RMM, gerenciamento de patches e o artigo específico sobre gerenciamento de patches Linux a partir de um RMM. Para testar com uma frota real, inicie um teste grátis.


