
Um RMM começa a gerar mais valor quando para de mostrar listas separadas.
Patches pendentes. Vulnerabilidades abertas. Alertas ativos. Dispositivos offline. Reinícios pendentes. Tickets sem fechar. Relatórios para clientes.
Se cada sinal vive sozinho, o técnico vira a camada de integração: abre uma tela, pula para outra, lembra contexto, decide prioridade e documenta manualmente. Esse fluxo não escala.
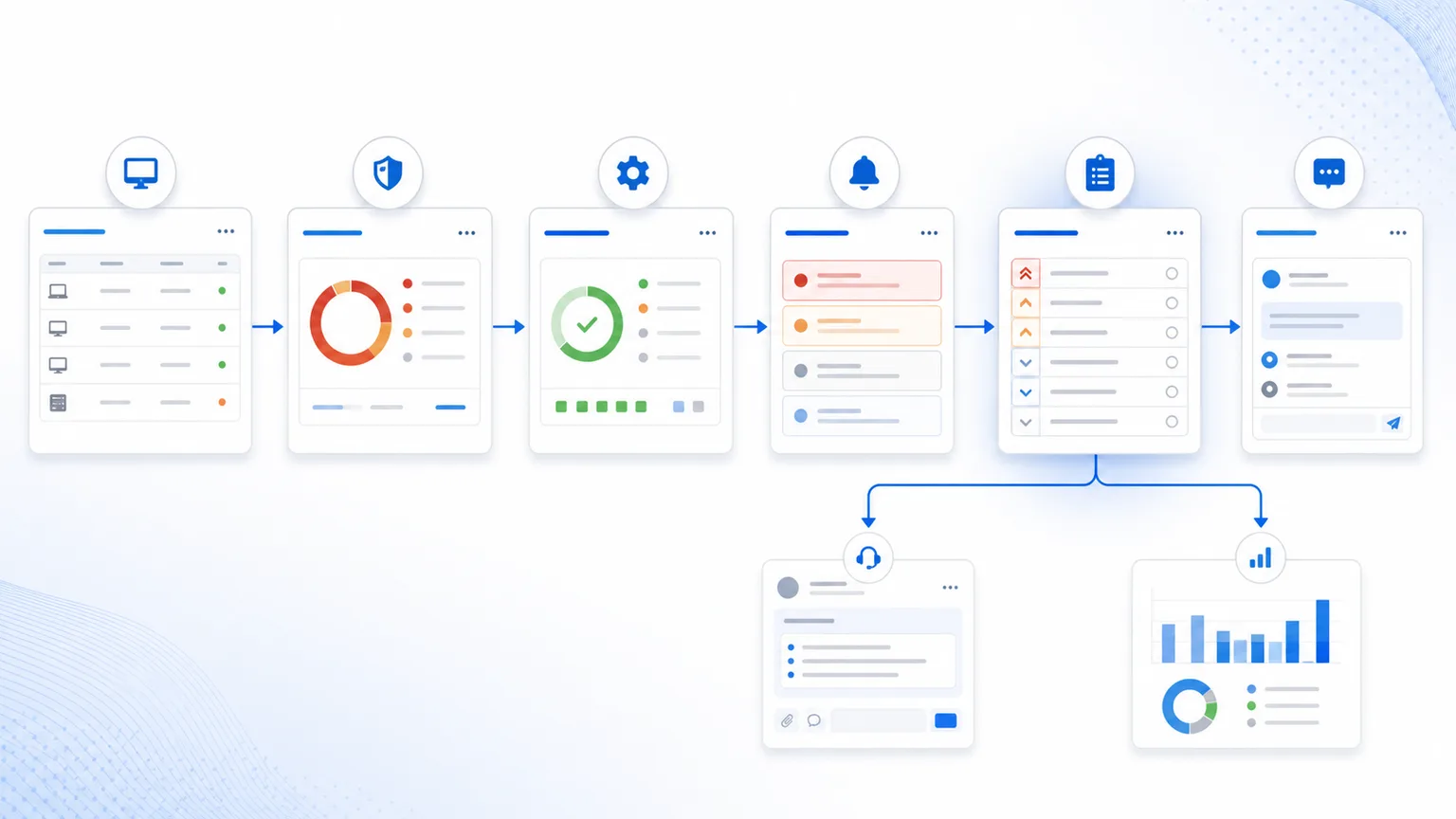
O estágio mais maduro de uma operação RMM é conectar esses sinais em uma fila de trabalho: o que importa primeiro, qual ação vem depois, quem assume, como verificar e como reportar.
1) Comece pelo inventário, porque tudo depende de escopo
Você não consegue priorizar o que não consegue localizar.
Antes de falar de CVE, patches ou alertas, você precisa saber quais endpoints existem, quais softwares rodam, qual sistema operacional usam, quais sinais recentes mostram e quão importantes são para a operação.
O inventário transforma um alerta genérico em uma pergunta concreta:
- qual dispositivo está afetado?
- qual software ou versão está envolvida?
- é um endpoint gerenciado ou apenas descoberto?
- existe usuário, cliente ou localização clara?
- há patches pendentes?
- existem alertas recentes relacionados?
- há tickets abertos para o mesmo dispositivo?
Por isso o fluxo completo conecta inventário, monitoramento de dispositivos e descoberta de rede. Sem escopo, qualquer priorização vira teoria.
2) Use vulnerabilidades para explicar risco, não para criar outra lista
Gestão de vulnerabilidades não deveria virar uma lista infinita de CVE.
Ela deve responder uma pergunta operacional:
que exposição existe na minha frota e que ação reduz esse risco?
Para responder, você precisa cruzar sinais:
| Sinal | O que acrescenta |
|---|---|
| Inventário de software | Onde o componente afetado existe |
| CISA KEV | Se uma vulnerabilidade tem exploração conhecida |
| EPSS | Probabilidade estimada de exploração nos próximos 30 dias |
| Estado do patch | Se existe ação disponível ou pendente |
| Criticidade do endpoint | Impacto se o equipamento falhar ou for comprometido |
Inventário de software
Onde o componente afetado existe
CISA KEV
Se uma vulnerabilidade tem exploração conhecida
EPSS
Probabilidade estimada de exploração nos próximos 30 dias
Estado do patch
Se existe ação disponível ou pendente
Criticidade do endpoint
Impacto se o equipamento falhar ou for comprometido
Esse enfoque evita tratar tudo como emergência. Também evita o problema oposto: ignorar risco porque ele ficou enterrado entre centenas de achados.
O guia sobre gestão de vulnerabilidades em um RMM aprofunda esse ponto: o valor está em transformar achados em decisões, não em colecionar identificadores.
3) Conecte patching com verificação
Aplicar um patch nem sempre significa fechar o risco.
Pode falhar. Pode exigir reinício. Pode aplicar só em alguns endpoints. Pode deixar uma versão vulnerável se a atualização não terminou corretamente.
Gestão de patches precisa de três momentos:
- Detecção: qual endpoint precisa de atualização.
- Execução: qual ação foi programada ou aplicada.
- Verificação: o que realmente mudou depois.
O NIST SP 800-40 trata patch management como um ciclo de planejamento, execução e acompanhamento. Em um RMM, esse ciclo deve aparecer em estados visíveis: pendente, aplicado, falhou, requer reinício, requer revisão ou exceção documentada.
Isso se conecta com patches de terceiros com WinGet e com o fluxo de patches da detecção à verificação. O objetivo não é disparar mais ações. É fechar mais pendências com evidência.
4) Use alertas para decidir urgência
Uma vulnerabilidade importante pode esperar uma janela de manutenção.
Mas se o mesmo endpoint também tem disco baixo, antivírus desabilitado, malware detectado, rajadas de login com falha ou um patch crítico com erro, a leitura muda.
Alertas ajudam a responder:
- existe sinal ativo?
- há impacto atual?
- a pendência pode virar incidente?
- vários sintomas aparecem no mesmo endpoint?
- suporte precisa atender isso hoje?
O Centro de ações em RMM existe para organizar esse tipo de sinal. Nem toda pendência merece a mesma urgência. A prioridade nasce do contexto: risco, impacto, estado técnico e cliente.
5) Transforme sinais em tickets quando há acompanhamento humano
Nem tudo deve virar ticket.
Mas quando um sinal exige conversa, aprovação, investigação, escalamento ou evidência de fechamento, ele precisa de acompanhamento.
Exemplos:
- patch com falha em endpoint crítico;
- vulnerabilidade aceita como risco pelo cliente;
- endpoint offline impedindo verificação de remediação;
- alerta recorrente que precisa de investigação;
- reinício pendente que exige coordenação;
- exceção que precisa voltar no próximo relatório.
É aí que o ticket conecta trabalho técnico com responsabilidade. O post sobre tickets de suporte em RMM cobre essa camada: status, prioridade, contexto de SLA, respostas, notas internas, endpoint relacionado e evidência.
6) Reporte avanço, não só atividade
O relatório não deve dizer "fizemos coisas".
Deve dizer o que mudou.
Um relatório RMM útil conecta:
- endpoints cobertos;
- patches aplicados e com falha;
- vulnerabilidades reduzidas ou aceitas;
- alertas atendidos;
- tickets abertos e fechados;
- riscos ainda pendentes;
- decisões que o cliente precisa tomar.
Isso muda a conversa com clientes MSP. Em vez de entregar uma lista enorme de alertas ou CVE, você consegue explicar: estes endpoints estavam expostos, estas ações foram executadas, estes casos precisam de aprovação e este risco continua aberto por este motivo.
Esse fluxo se conecta com relatórios RMM para clientes e auditorias. O relatório fecha o ciclo; não é uma exportação isolada.
7) Como fica o fluxo completo
Um fluxo RMM completo pode ser lido assim:
| Etapa | Pergunta | Saída esperada |
|---|---|---|
| Inventário | Onde existe o ativo ou software? | Escopo real |
| Vulnerabilidade | Qual risco se aplica? | Prioridade técnica |
| Patch | Que ação reduz o risco? | Remediação executável |
| Alerta | Há sinal ativo ou impacto atual? | Urgência operacional |
| Action Center | O que deve ser atendido primeiro? | Fila priorizada |
| Ticket | Quem acompanha? | Responsabilidade e contexto de SLA |
| Relatório | O que mudou e o que falta? | Evidência para cliente |
Inventário
Onde existe o ativo ou software?
Escopo real
Vulnerabilidade
Qual risco se aplica?
Prioridade técnica
Patch
Que ação reduz o risco?
Remediação executável
Alerta
Há sinal ativo ou impacto atual?
Urgência operacional
Action Center
O que deve ser atendido primeiro?
Fila priorizada
Ticket
Quem acompanha?
Responsabilidade e contexto de SLA
Relatório
O que mudou e o que falta?
Evidência para cliente
O Lunixar RMM é construído em torno dessa lógica: inventário, monitoramento, alertas, patches, contexto de vulnerabilidades, relatórios e suporte não deveriam operar como ilhas. Eles devem ajudar técnicos a decidir mais rápido e fechar com melhor evidência.
Para avaliar o fluxo completo, veja Lunixar RMM, gerenciamento de patches, alertas, preços e o teste grátis de 2 semanas.


