
Un RMM empieza a generar valor cuando deja de mostrar listas separadas.
Parches pendientes. Vulnerabilidades abiertas. Alertas activas. Dispositivos offline. Reinicios pendientes. Tickets sin cerrar. Reportes para cliente.
Si cada señal vive sola, el técnico termina haciendo integración mental: abrir una pantalla, saltar a otra, recordar contexto, decidir prioridad y documentar a mano. Ese flujo no escala.
El cierre de una operación RMM madura es conectar esas señales en una cola de trabajo: qué importa primero, qué acción sigue, quién lo toma, cómo se verifica y cómo se reporta.
1) Empieza con inventario, porque todo depende de alcance
No puedes priorizar lo que no puedes ubicar.
Antes de hablar de CVE, parches o alertas, necesitas saber qué endpoints existen, qué software tienen, qué sistema operativo usan, qué señales recientes muestran y qué tan importantes son para la operación.
El inventario convierte una alerta genérica en una pregunta concreta:
- ¿qué equipo está afectado?
- ¿qué software o versión está involucrada?
- ¿es un endpoint administrado o descubierto?
- ¿tiene usuario, cliente o ubicación clara?
- ¿hay parches pendientes?
- ¿hay alertas recientes relacionadas?
- ¿hay tickets abiertos sobre el mismo equipo?
Por eso el flujo completo conecta inventario, monitoreo de dispositivos y descubrimiento de red. Sin alcance, cualquier priorización se vuelve teórica.
2) Usa vulnerabilidades para explicar riesgo, no para crear otra lista
La gestión de vulnerabilidades no debería ser una lista interminable de CVE.
Debe responder una pregunta operativa:
¿qué exposición existe en mi flota y qué acción la reduce?
Para eso necesitas cruzar señales:
| Señal | Qué aporta |
|---|---|
| Inventario de software | Dónde existe el componente afectado |
| CISA KEV | Si una vulnerabilidad ya tiene explotación conocida |
| EPSS | Probabilidad estimada de explotación en los próximos 30 días |
| Estado del parche | Si existe una acción disponible o pendiente |
| Criticidad del endpoint | Impacto si el equipo falla o queda comprometido |
Inventario de software
Dónde existe el componente afectado
CISA KEV
Si una vulnerabilidad ya tiene explotación conocida
EPSS
Probabilidad estimada de explotación en los próximos 30 días
Estado del parche
Si existe una acción disponible o pendiente
Criticidad del endpoint
Impacto si el equipo falla o queda comprometido
Ese enfoque evita tratar todo como emergencia. También evita lo contrario: ignorar un riesgo porque aparece perdido entre cientos de hallazgos.
El post sobre gestión de vulnerabilidades en un RMM explica este punto a detalle: el valor está en convertir hallazgos en decisiones, no en coleccionar identificadores.
3) Conecta patching con verificación
Aplicar un parche no siempre significa cerrar el riesgo.
Puede fallar. Puede requerir reinicio. Puede aplicar solo a ciertos endpoints. Puede dejar una versión vulnerable si la actualización no terminó limpia.
Por eso la gestión de parches debe tener tres momentos:
- Detección: qué endpoint necesita actualización.
- Ejecución: qué acción se programó o se aplicó.
- Verificación: qué cambió realmente después.
NIST SP 800-40 trata el patch management como un ciclo de planeación, ejecución y seguimiento. En RMM, ese ciclo debe aterrizar en estados visibles: pendiente, aplicado, fallido, requiere reinicio, requiere revisión o excepción documentada.
Esto se conecta con parches de terceros con WinGet y con flujo de parches: detección a verificación. El objetivo no es disparar más acciones. Es cerrar más pendientes con evidencia.
4) Usa alertas para decidir urgencia
Una vulnerabilidad importante puede esperar a una ventana de mantenimiento.
Pero si el mismo endpoint también tiene disco bajo, antivirus deshabilitado, malware detectado, rachas de login fallido o un parche crítico fallido, la lectura cambia.
Las alertas ayudan a responder:
- ¿hay señal activa?
- ¿hay impacto actual?
- ¿hay riesgo de que el pendiente se vuelva incidente?
- ¿hay varios síntomas en el mismo endpoint?
- ¿hay trabajo que soporte debe atender hoy?
El Centro de acciones en RMM existe para ordenar ese tipo de señales. No todo pendiente merece la misma urgencia. La prioridad sale de contexto: riesgo, impacto, estado técnico y cliente.
5) Convierte señales en tickets cuando necesitan seguimiento humano
No todo debe convertirse en ticket.
Pero cuando una señal requiere conversación, aprobación, investigación, escalamiento o evidencia de cierre, sí necesita seguimiento.
Ejemplos:
- parche fallido en equipo crítico;
- vulnerabilidad con riesgo aceptado por el cliente;
- endpoint offline que impide verificar remediación;
- alerta recurrente que necesita investigación;
- reinicio pendiente que requiere coordinación;
- excepción que debe revisarse en el siguiente corte.
Ahí el ticket conecta la operación técnica con responsabilidad. El post sobre tickets de soporte en RMM cubre esa parte: estado, prioridad, SLA, respuesta, notas internas, endpoint relacionado y evidencia.
6) Reporta avance, no solo actividad
El reporte no debe decir "hicimos cosas".
Debe decir qué cambió.
Un reporte RMM útil conecta:
- endpoints cubiertos;
- parches aplicados y fallidos;
- vulnerabilidades reducidas o aceptadas;
- alertas atendidas;
- tickets abiertos y cerrados;
- riesgos que siguen pendientes;
- decisiones que necesita tomar el cliente.
Esto cambia la conversación con clientes MSP. En vez de entregar una lista enorme de alertas o CVE, puedes explicar: estos endpoints estaban expuestos, estas acciones se ejecutaron, estos casos requieren aprobación y este riesgo sigue abierto por este motivo.
Ese flujo conecta con reportes RMM para clientes y auditorías. El reporte es el cierre del ciclo, no una exportación aislada.
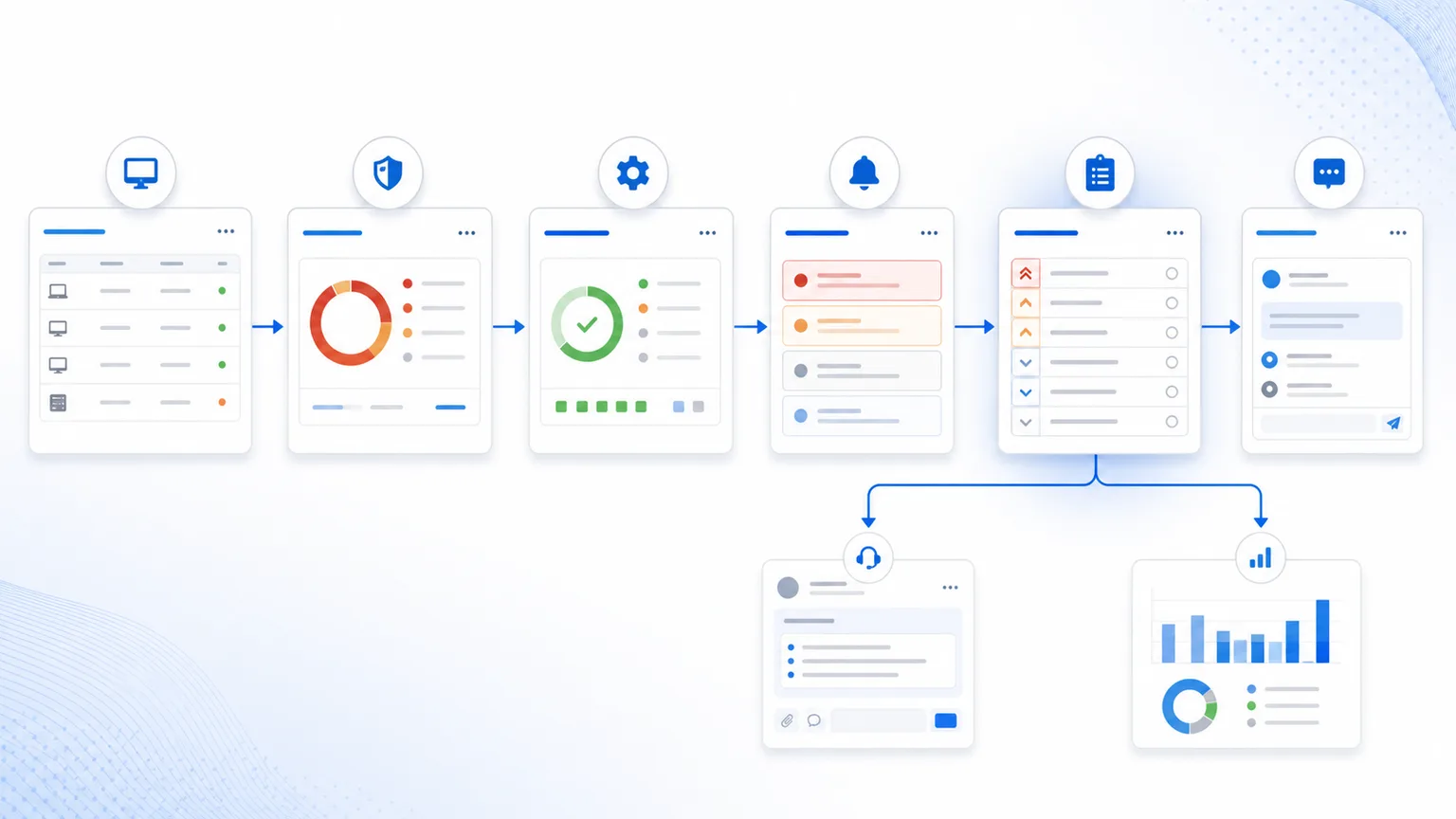
7) Cómo se ve el flujo completo
Un flujo RMM completo puede leerse así:
| Paso | Pregunta | Salida esperada |
|---|---|---|
| Inventario | ¿Dónde existe el activo o software? | Alcance real |
| Vulnerabilidad | ¿Qué riesgo aplica? | Prioridad técnica |
| Parche | ¿Qué acción reduce el riesgo? | Remediación ejecutable |
| Alerta | ¿Hay señal activa o impacto actual? | Urgencia operativa |
| Action Center | ¿Qué debe atenderse primero? | Cola priorizada |
| Ticket | ¿Quién da seguimiento? | Responsabilidad y SLA |
| Reporte | ¿Qué cambió y qué falta? | Evidencia para cliente |
Inventario
¿Dónde existe el activo o software?
Alcance real
Vulnerabilidad
¿Qué riesgo aplica?
Prioridad técnica
Parche
¿Qué acción reduce el riesgo?
Remediación ejecutable
Alerta
¿Hay señal activa o impacto actual?
Urgencia operativa
Action Center
¿Qué debe atenderse primero?
Cola priorizada
Ticket
¿Quién da seguimiento?
Responsabilidad y SLA
Reporte
¿Qué cambió y qué falta?
Evidencia para cliente
Lunixar RMM está diseñado alrededor de esa lógica: inventario, monitoreo, alertas, parches, contexto de vulnerabilidades, reportes y soporte no deberían operar como islas. Deben ayudar a que el técnico decida más rápido y cierre con más evidencia.
Para evaluar el flujo completo, revisa Lunixar RMM, gestión de parches, alertas, precios y la prueba gratis de 2 semanas.


